Text Similarity Analysis with C++: Detecting Duplicate Content
Hello Everyone
I'm AhsanSharif From Pakistan
Greetings to you all, hope you all are well and enjoying a happy moment of life with steem. I'm also good Alhamdulillah. |
|---|

Canva Design
My project today is for calculating similarity or you can say it is for detecting plagiarism. The method will be something like this: there will be two files in it, these files will be compared, and the plagiarism of both of them will be detected.
Key Points:
- This will remove punctuation and convert the text to lower case, eliminating common words such as in the end and etc. It will only focus on words that are meaningful.
- It will compare two files in the app, process their text, and then check for similarity based on a word sequence.
- This will calculate the percentage of text similarity, how many words are common in both files, and what percentage.
- It is designed in such a way that it will check the similarity of the text and see if the other file is not given in the rewritten version and will focus on the meaningful full words and ignore all the other common phrases.
- In this, we have to take two text files, both of these text files will contain our text and we will compare both of them.
Explanation
Now let's move on to the functionalities of our project, and how each function is working.
Stop Words:
In this entire set, we have included words that are very common and that we want to exclude from our text. All these words do not help us determine whether two files are similar or have been rewritten. We will exclude them and check for duplication based on the specific words that are present.

Preprocessing Text:
Here, using this remove_if and ::ispunct, we remove the punctuations like periods, commas, etc.
Additionally, using transform and ::tolower, converts characters to lowercase and ensures that it is case-insensitive.

Splitting & Removing Stop Words:
The text is split into individual words using a stringstream. As each word comes out, the code then checks if it is a stop word. If it is not a stop word, it adds it to the words vector.
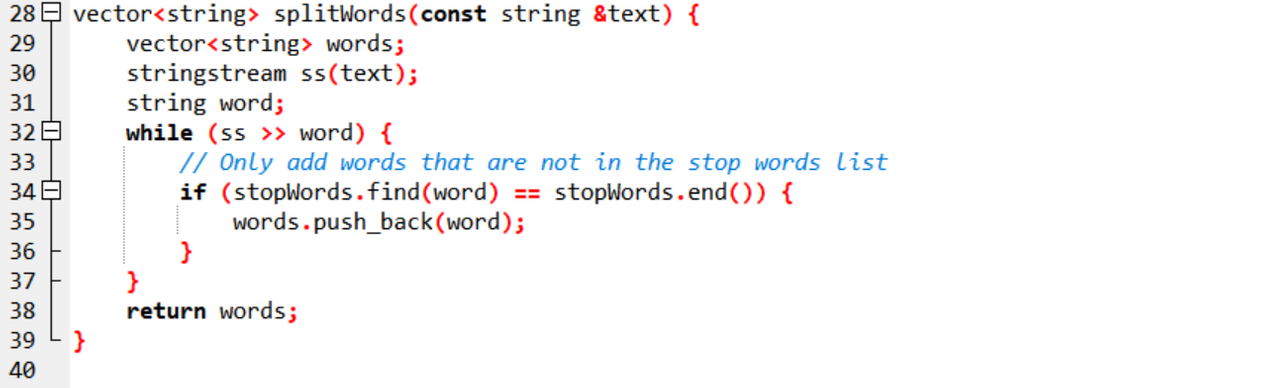
Read File Contents:
This function is used to read a file. It reads the entire content. If the file is not open, then it shows an error message.

Calculate Similarity:
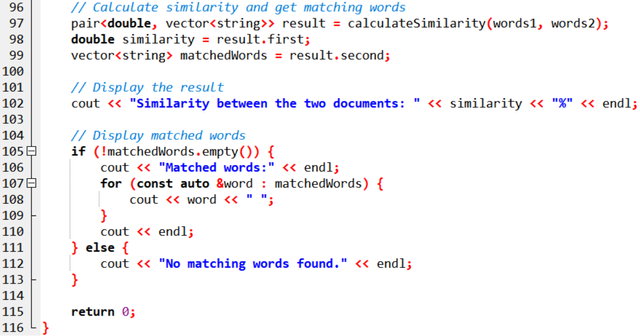
Two lists of words are converted into one set unordered_set to eliminate duplication. It counts the common words between these two sets by checking them.
When similarity is checked as a percentage, it does so by taking into account the unique words between the two sets. Finally, this function shares the list of matching words between these two sets and reports the percentage.

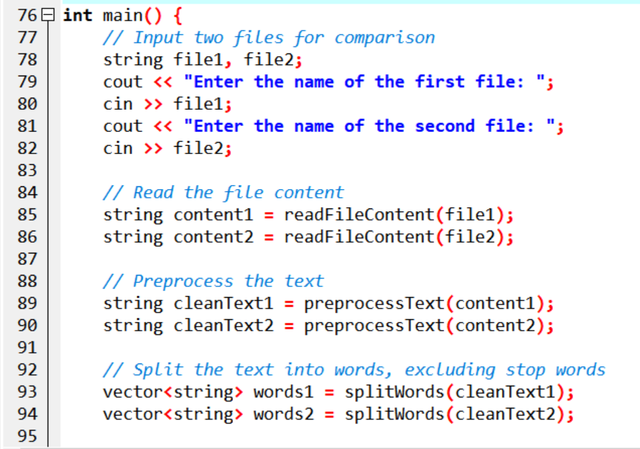
Main Function:
First, the file input is taken from the user, the user will put the names of both the files there, after which this main function will read these two files and store them in a string, then the result of both of them will be processed, there will be pre-processing in which punctuation will be removed and it will be converted to lower case, then after that the stop words present in both will be eliminated and later the similarity words in it will be calculated and their percentage and their list will be shown in the result.
 |  |
|---|
C++ Code File
Output
- 01.
First of all, we will input the same data in both the two text files we have and check both of them by running this program. Then what result do we get below?
- 02.
Now we have to put different data in both the text files and now we will see how much similarity there is between them.
This was my project for today in which we can compare duplicate words in two files. Thank you all very much for stopping by. I hope you guys liked this mini-project of mine. I would like to invite @karianaporras, @jospha, @syedbaider, and @chant to join this challenge club.
Cc:
@kafio @mohammadfaisal @alejos7ven

Bro you working on a Great project, Your plagiarism detector is look well-structured and easy to follow.
I suggest you to consider adding more features like ignoring common phrases such as (The starting of an article like How are you, I hope you well, bla bla bla...) or sentences, and supporting multiple file formats.
Also, you could improve the accuracy by using more advanced algorithms like Levenshtein distance or Longest Common Subsequence. Well wish you all the best for your project.
Thank you so much for the valuable feedback.
This project already ignore the comma's phrases and also eliminate the common words like the, and, or, that, this etc. After eliminating these words this project check the specific words that have a specific meaning.
Also I will do my best to improve this project by adding more functionalities.
Thank you I wish success too.
That's sounds good, keep up the good work bro ...
Hola Amigo gracias por compartir otro proyecto en C++ relacionado al manejo de texto en este lenguaje, en esta ocasión tengo varias sugerencias para ti para mejorar un poco la experiencia de uso.
Tal vez sea mucho mejor evaluar la carpeta del proyecto y listar los archivos .txt que estén presentes y pedirle al usuario que los selecciones simplemente escribiendo un número que le hayas asignado a cada archivo así se evitará tener que escribir el nombre de los archivos que vas a comparar.
Como recomendación extra puedo decirte que hagas un solo video fusionado y editado con algunos títulos y transiciones, si haces esto puedes utilizar la etiqueta #steemvideo.
Sure thank you so much for the valuable feedback.