[개발이야기#07] 트랜스포머 모델을 활용한 '영 -> 한' 번역하기 (4) 영문->한글 번역 테스트
글 작성일: 2024년 9월 28일 (토)
안녕하세요. 요거트 @yoghurty 입니다!
파이썬/인공지능 공부를 위해
트랜스포머 모델을 이용한 영문을 한글로 번역할 수 있는 (간단한)번역기를 직접 만들어 보고 있습니다.
이를 위해 제가 참고하는 글은 다음의 두 가지입니다.
- [개발이야기#017] 파이썬/인공지능 영어를 한글로 번역해보자. - 트랜스포머모델 두번째
- 친절한 영어-한국어 번역기 만들기 A Gentle Introduction to Creating an English-to-Korean translator with Transformers
'영->한' 번역하기 프로젝트로 계획된 총 4회 중 오늘은 4번째 - 생성된 번역기를 이용한 영문->한글 번역 테스트 입니다.
오늘은 영문->한글 번역 테스트를 해보려고 하는데요,
지난 3회차에 생성한 모델이 있어야 실습(?)이 가능합니다. ^^
(1회차) 학습용 데이터 셋 준비
👉 [개발이야기#03] 파이썬/인공지능- 트랜스포머 모델을 활용한 '영 -> 한' 번역하기 (1) 학습용 데이터셋 준비(feat. 가야태자님)
(2회차) 컴퓨터가 학습을 할 수 있도록 학습용 데이터 사전 작업(토크나이징, tokenizing)
👉 [개발이야기#05] 파이썬/인공지능- 트랜스포머 모델을 활용한 '영 -> 한' 번역하기 (2) 데이터 사전 작업-토크나이징
(3회차) 학습을 통한 모델(번역기) 생성
👉 [개발이야기#06] 트랜스포머 모델을 활용한 '영 -> 한' 번역하기 (3) 학습을 통한 모델(번역기) 생성
(4회차) 생성된 번역기를 이용한 영문->한글 번역 테스트
가상환경(engtokor) 구동 및 필요 패키지 설치
영문을 한글로 번역하기 위한 프로젝트 진행을 위해 지난시간-(1)회차-에 생성한 콘다 가상환경 engtokor 을 구동시켜 줍니다.
conda activate engtokor
생성된 번역기를 이용한 영문->한글 번역 테스트
이번에는 지난 시간에 생성한 모델을 이용해서 영문->한글 번역 테스트를 해보겠습니다.
크게 4가지 작업으로 나누어집니다.
--> 지난 시간에 생성한 모델을 불러온 뒤
--> 번역할 데이터를 준비하고 -
--> 번역하고
--> 출력하는 순서로 작업을 해보겠습니다.
1. 지난시간에 생성한 모델을 불러 오기
작업하는 폴더에는 지난 시간에 생성한 모델이 results 폴더 아래에 위치하도록 해주세요~ ^^
우리가 열심히 학습시켰던 모델을 이용하겠습니다.
model_dir = "./results"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSeq2SeqLM.from_pretrained(model_dir)
2. (1회차)때 테스트 용으로 나누어 놓았던 데이터를 이용하여 번역해 볼 영어 문장 준비하기
첫 작업시 우리는 데이터를 train, valid, test 의 세 종류로 나누었습니다.
테스트 용으로 10,000건을 준비했었죠?
한 덩어리로 되어있는 데이터셋을 학습용train, 검증용valid, 테스트test 용도의 세 그룹으로 분할하여 재조직화 합니다.
각 그룹별 샘플의 수는 다음과 같이 나누어줍니다.num_train = 1200000
num_valid = 90000
num_test = 10000
기존에 작업해 두었던 데이터셋을 읽어와서 토큰화된 데이터셋으로 만들어 준비하겠습니다.
따라서, 이번에 작업하시는 폴더에 "train.tsv", "valid.tsv", "test.tsv" 파일들이 함께 있는지 꼭 확인해 주세요! ^^
data_files = {"train": "train.tsv", "valid": "valid.tsv", "test": "test.tsv"}
dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
- 토큰화된 데이터 셋을 준비하는 나머지 코드들은 아래쪽에 전체코드를 참고해주세요~ ^^
3. 준비한 테스트용 데이터를 입력하여 출력(번역결과물) 생성하기!
아래와 같이 (3회차)에서 열심히 학습했던 모델에게
테스트용 데이터셋을 주면서
한글 문장으로 번역하라고 일을 좀 시켜봅니다! ^^
koreans = model.generate(
**test_input,
max_length=max_token_length, num_beams=5,
)
4. 결과물 출력하기
입력한 영어 문장(English), 모범답안(Reference) 그리고 이번에 모델을 이용해 우리가 한글로 번역한 문장(Translated)을 비교해 볼 수 있도록 예쁘게 출력해 보겠습니다. ^^
for s in zip(eng_sents, references, preds):
print('English :', s[0])
print('Reference :', s[1])
print('Translated:', s[2])
print('\n')
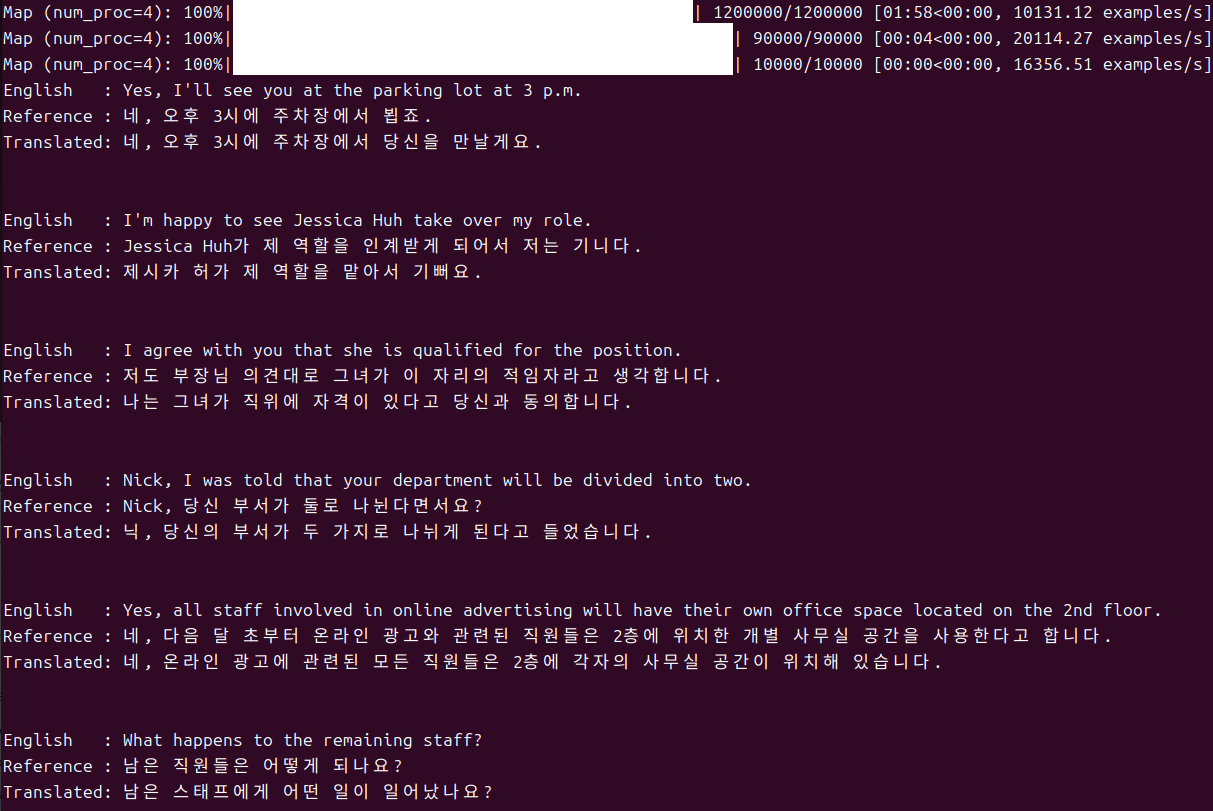
첫줄, English 라고 되어있는 부분이 번역하려는 영어 문장입니다.
두번째줄, Reference 줄이 모범답안입니다. 영어문장을 한글로 번역해 놓은 답안이죠.
세번째줄, Translated 줄은, 우리가 학습시켰던 모델을 이용해서 이번에 번역해 본 결과입니다.
마무리
이번 작업은
영어를 한글로 번역할 수 있는 모델(번역기)을 만들기 위해,
지난 시간(3회차)에 데이터를 학습시켜 생성한 모델을 이용하여
테스트 셋에 있는 영어 문장을 한글 문장으로 번역시켜보았습니다!
번역 결과를 보면,
reference(모범답안)와 비교했을때, 조금 차이가 있는 부분도 보이는데요...
그래도 1회 정도 학습시킨 것을 감안하면 봐줄만한 결과가 아닌가 싶습니다!
무엇보다도 저의 로컬PC에서 학습시킨 모델을 이용한 번역 결과물이라는 점에서 뭔가 뿌듯함을 느낄 수 있었습니다! ^^
테스트 셋으로만 번역을 해봤는데...
다음에, 기회가 되면, 임의의 문장(테스트 셋과 같은 모범답안은 없겠죠?)을 이용해서 한 번 번역시켜보도록 하겠습니다~
이상 요거트 였습니다!
고맙습니다~ ^^
<4회차 전체코드>
4회차 전체 코드입니다.
3회차에서 생성한 모델(result폴더)과 데이터 파일("train.tsv", "valid.tsv", "test.tsv")들이 있는 작업 폴더에서
이 코드를 사용하시면, 번역 결과물을 확인 가능하십니다.
(만약, 에러나면 댓글 달아주세요~ ^^)
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from transformers import DataCollatorForSeq2Seq
from datasets import load_dataset
from torch.utils.data import DataLoader
import multiprocessing
import numpy as np
model_ckpt = "KETI-AIR/ke-t5-base"
max_token_length = 64
# 다음 명령으로 학습된 모델을 불러온다.
model_dir = "./results"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForSeq2SeqLM.from_pretrained(model_dir)
model.cpu();
# 테스트 셋에서 몇 개 문장을 가져와 번역해보자.
## 테스트 셋의 데이터는 이미 토큰화가 되어있는 데이터이다. 처음 작업시 우리는 데이터를 train, valid, test 의 세 종류로 나누어 놓았었다.
## 새롭게 작업하는 경우, 기존에 작업해 두었던 데이터셋을 다시 읽어와서 다시 토큰화된 데이터셋으로 만들어야하므로, "train.tsv", "valid.tsv", "test.tsv" 파일이 있는 폴더에서 실행한다.
### dataset 읽어오기
data_files = {"train": "train.tsv", "valid": "valid.tsv", "test": "test.tsv"}
dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
### Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
def convert_examples_to_features(examples):
model_inputs = tokenizer(examples['en'],
text_target=examples['ko'],
max_length=max_token_length, truncation=True)
return model_inputs
NUM_CPU = multiprocessing.cpu_count()
tokenized_datasets = dataset.map(convert_examples_to_features,
batched=True,
remove_columns=dataset["train"].column_names,
num_proc=NUM_CPU)
# 만들어 놓은 tokenized_datasets과 data_collator를 pytorch DataLoader에 그대로 전달해서 데이터 로더를 만들 수 있다.
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
test_dataloader = DataLoader(
tokenized_datasets["test"], batch_size=32, collate_fn=data_collator
)
# 이터레이터로 만들어 한 미니 배치만 가져온다.
test_dataloader_iter = iter(test_dataloader)
test_batch = next(test_dataloader_iter)
# 콜레이터에 의해 반환된 미니 배치에는 labels, decoder_input_ids 따위도 가지고 있으므로
# 모델에 입력하기 위해 input_ids, attention_mask만 남긴다.
test_input = { key: test_batch[key] for key in ('input_ids', 'attention_mask') }
# 준비된 데이터를 입력하여, 출력(번역결과물)을 생성 한다.
koreans = model.generate(
**test_input,
max_length=max_token_length,
num_beams=5,
)
# 이제 입력문장, 정답 그리고 생성된 문장을 비교해 볼 수 있도록 예쁘게 출력해보자.
labels = np.where(test_batch.labels != -100, test_batch.labels, tokenizer.pad_token_id)
eng_sents = tokenizer.batch_decode(test_batch.input_ids, skip_special_tokens=True)[10:20]
references = tokenizer.batch_decode(labels, skip_special_tokens=True)[10:20]
preds = tokenizer.batch_decode( koreans, skip_special_tokens=True )[10:20]
for s in zip(eng_sents, references, preds):
print('English :', s[0])
print('Reference :', s[1])
print('Translated:', s[2])
print('\n')
Upvoted! Thank you for supporting witness @jswit.
새로 학습한 모델이 레퍼런스보다 번역을 잘하는 것 같습니다. ^^
ㅎㅎ 좋게 봐주셔서 감사합니다~ ^^
대단하십니다. 그렇게 복잡하게 안보이는데 진짜 번역이 되네요.
예~ 저도 놀랐습니다~ 별로 한 것 없는데~ 번역이 되네요! ^^