구글의 서비스 수준 관리

서비스 수준 목표
크리스 존스(Chris Jones), 존 윌크스(John Wilkes), 니얼 머피(Nial Murphy), 코디 스미스(Cody Smith)
서비스를 운영하는 데 있어 가장 중요한 지표들과 이 지표들을 측정하고 평가하는 방법에 대한 올바른 이해 없이는 서비스를 올바르게, 알아서 잘 돌아가도록 관리한다는 것은 불가능하다.
그래서 이번에는 내부 API가 됐든 아니면 공개된 제품이 됐든, 사용자에게 필요한 서비스의 적정 수준을 정의하고 제공하는 방법에 대해 이야기하고자 한다.
이 내용은 우리 저자들의 직감과 경험, 그리고 사용자가 서비스 수준 척도(Service Level Indicator, SLI), 서비스 수준 목표(Service Level Objectives, SLO), 서비스 수준 협약(Service Level Agreements, SLA) 등을 어떻게 정의하고 있는지에 대한 이해를 바탕으로 하고 있다.

이 세 가지를 살펴보면 주요 지표들의 기본 속성과 각 지표들의 적정 값, 그리고 기대했던 수준의 서비스를 제공하지 못했을 때의 대처 방안 등을 알 수 있다.
결국 어딘가에 문제가 발생했을 때 올바른 지표를 참고하여 적절한 행동을 취할 수 있으며, SRE팀은 이런 지표들을 확인함으로써 서비스가 문제없이 동작 중이라는 확신을 가질수 있다.
이 장에서는 우리가 지표의 모델링과 선택, 그리고 분석 과정에서 발생하는 문제들을 해결하는 데 사용했던 프레임워크를 소개한다.
이런 류의 설명은 예제가 없으면 너무 추상적으로 들릴 수 있다.
세익스피어: 예제 서비스
서비스가 구글의 프로덕션 환경에 배포되는 방식을 설명하기 위해 여러 가지 구글의 기술들을 활용하는 예제 서비스를 살펴보도록 하자.
이번에 살펴볼 예제 서비스는 특정 단어가 세익스피어의 작품 중 어느 것에서 사용되고 있는지를 검색해주는 서비스다.
이 시스템은 크게 두 부분으로 구성된다.
- 세익스피어의 작품들을 텍스트로 읽어 인덱스를 생성하고 이를 빅데이블에 저장하는 일괄 작업 컴포넌트, 이 작업은 단 한 번 실행되거나 어쩌다가 한 번(지금까지 몰랐던 작품이 발견된다면)실행된다
- 최종 사용자의 요청을 처리할 애플리케이션 프런트엔드, 이 작업은 모든 시간대의 사용자들이 세익스피어의 책을 검색하길 원할 것이므로 항상 실행된다.
일괄 작업 컴포넌트는 맵리듀스를 이용해 세 가지 과정을 처리한다.
매핑 과정에서는 세익스피어의 텍스트를 읽고 이를 단어 단위로 쪼갠다.
여러 개의 워크 프로세스를 병렬로 실행하면 이 작업을 빠르게 수행할 수 있다.
셔플(shuffle) 과정에서는 발견된 단어들을 정렬한다.
리듀스 과정에서는 튜플(단어와 단어의 위치)을 생성한다.
각각의 튜플은 빅테이블의 로우(row)에 기록되며, 이때 단어가 키로 사용된다.

요청의 흐름
그림에서 사용자의 요청이 서비스되는 과정을 보여준다. 먼저 사용자가 브라우저를 이용해 shakespear.google.com에 접속한다. 이때 적절한 IP 주소를 얻기 위해 사용자의 장치는 DNS 서버를 통해 주소를 해석한다.(1)
이 요청은 GSLB와 통신하는 구글의 DNS 서버를 통해 처리 된다. GSLB는 여러 지역의 프런트엔드 서버 간의 부하를 추적하므로 현재 사용자에게 적당한 서버의 IP 주소를 전달한다.브라우져는 이 IP 주소에서 동작하는 HTTP 서버에 연결한다. 이 서버(GFE, 또는 구글 프런트엔드라고 부른다)는 TCP 연결을 종료하는 리버스 프록시(reverse proxy)(2)다.
GFE는 어떤 서비스(웹 검색, 지도 혹은 예제의 경우 세익스피어 서비스)가 필요한지를 탐색한 후 GSLB를 이용하여 사용할 수 있는 세익스피어 프런트엔드 서버를 찾는다. 그런 다음 서버에세 HTML 요청을 담은 RPC를 전달한다.(3)
세익스피어 서버는 HTML 요청을 분석하여 탐색할 단어를 포함하는 프로토콜 버퍼를 구성한다. 세익스피어 프런트엔드 서버는 이제 세익스피어 백엔드 서버에 연결해야 한다. 프런트엔드 서버는 GSLB에 연결하여 자신이 연결할 백엔드 서버의 BNS 주소를 얻는다(4).
이 세익스피어 백엔드 서버는 빅테이블 서버에 연결하여 필요한 데이터를 얻는다.(5)
사용자가 탐색한 단어에 관한 결과는 응답 프로토콜 버퍼에 기록된 후 세익스피어 백엔드 서버에 전달된다.
백엔드 서버는 프로토콜 버퍼를 다시 세익스피어 프런트앤드 서버에 전달한다.
프런트엔드 서버는 전달된 데이터를 바탕으로 HTML을 구성한 후 사용자에게 전달한다.이런 일련의 이벤트들은 눈 깜짝할 사이에 실행된다. 아마 몇 백 밀리초면 충분한 것이다. 하지만 여러 서비스들이 연결되어 동작하므로 잠재적인 오류가 발생할 수 있다. 특히 GSLB에 문제가 발생하면 끝장이다.
그러나 구글의 엄격한 테스트 및 배포 정책과 더불어 사전 장애 복구 정책 덕분에 사용자들이 기대하는 안정적인 서비스를 제공할 수 있다. 이 덕분에 사람들이 인터넷 연결에 문제가 없는지 확인하고자 할 때 www.google.com에 접속해보는 것이다.

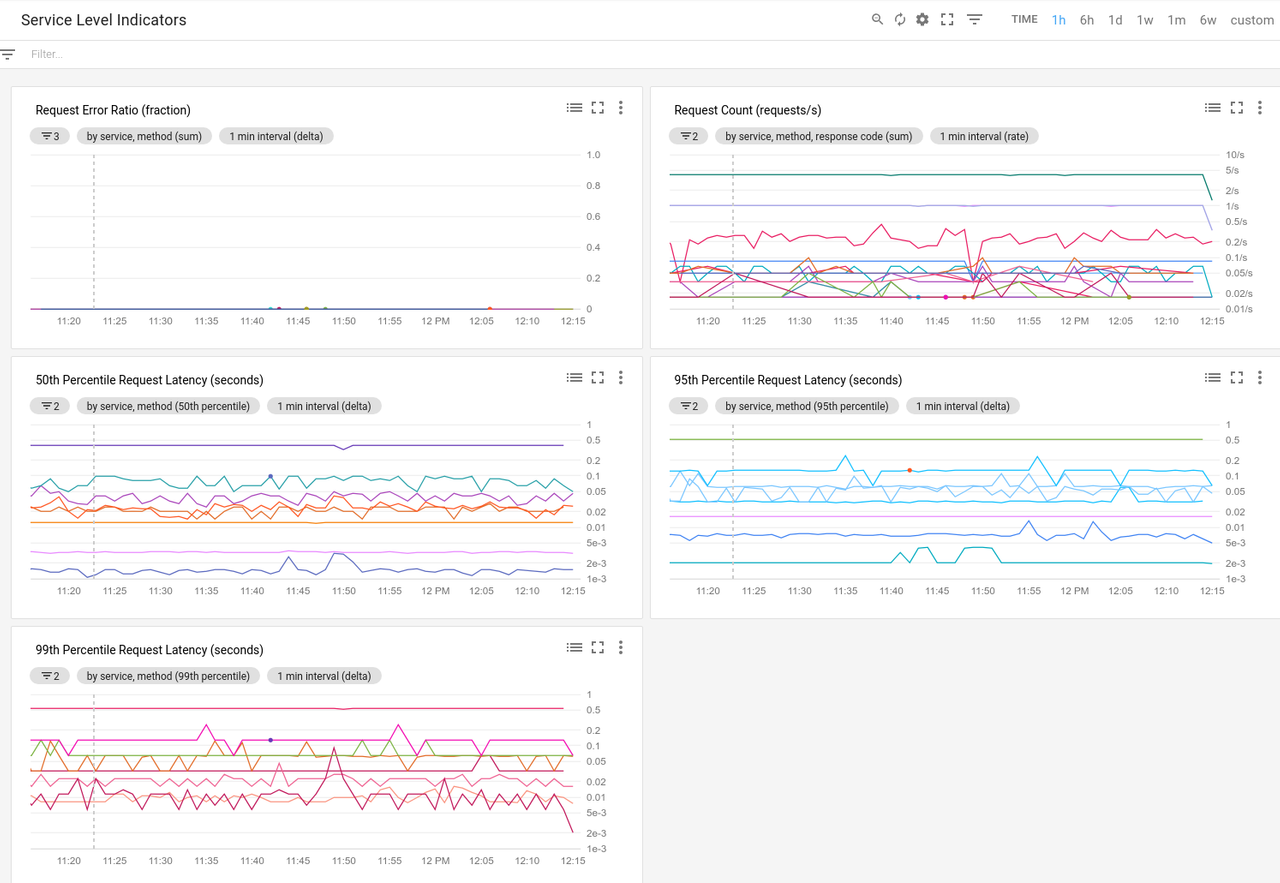
서비스 수준 관련 용어척도SLI는 서비스 수준 척도(Service Level Indicator)를 의미하며, 서비스 수준을 판단할 수 있는 몇 가지를 정량적으로 측정한 값이다.
대부분의 서비스들은 핵심 SLI로서 요청에 대한 응답 속도(요청에 대한 응답이 리턴되기까지의 시간)를 꼽는다. 그 외에도 시스템이 수신한 전체 요청 수 대비 에러율, 그리고 초당 처리할 수 있는 요청 수를 의미하는 시스템 처리량(system throughput) 등이 있다. 측정된 값들은 합산되기도 한다.

즉, 일정 기간 동안 측정한 값들을 모아 비율이나 평균 혹은 백분율(percentile) 등을 계산한다.
알고자 하는 서비스 수준의 SLI를 직접 측정하는 것이 이상적이기는 하지만 경우에 따라서는 필요한 값을 얻어내거나 해석하기에 어려워 그에 준하는 대체 값을 사용하는 경우도 있다.
예를 들어 클라이언트 측의 응답 속도를 측정하는 것이 사용자와 관련해서 조금 더 의미가 있게지만 우리 입장에서는 서버의 응답 속도만을 측정할 수 있다.SRE가 중요하게 생각하는 SLI 중 하나는 가용성, 즉 서비스가 사용 가능한 상태로 존재하는 시간의 비율이다.
이 값은 주로 올바른 행태의 요청이 성공적으로 처리된 비율을 의미하며 수율(yield, 생산된 전체 제품 중 불량이 없는 제품의 비율을 말하며, 여기서는 서버가 받은 요청 대비 성공적으로 응답한 비율을 의미한다.)이라고도 한다.(이와 유사하게, 데이터 저장소 시스템에서는 오랜 시간에 걸쳐 데이터를 보관하는 기준인 내구성(durability) 역시 중요한 지표).
비록 100% 가용성은 실현이 불가능하지만, 100%에 가까운 가용성은 얼마든지 달성할 수 있으며, 업계에서는 통상 고가용성을 여러 개의 '9'를 사용해서 백분율로 표현한다.예를 들어 99%의 가용성과 99.999%의 가용성은 각각 '9 두 개'와 '9 다섯 개' 가용성으로 표현한다. 그리고 현재 구글 컴퓨트 엔진(Google Compute Engine, GCE)은 '9 세 개 반', 즉 99.95%의 가용성을 목표로 하고 있다.
목표SLO는 서비스 수준 목표(Service Level Objective)를 의미하며, SLI에 의해 측정된 서비스 수준의 목표 값 혹은 일정 범위의 값을 의미한다.
그래서 SLO는 SLI ≤ 목표치 또는 최솟값 ≤ SLI ≤ 최댓값으로 표현할 수 있다.
예를 들어 우리가 세익스피어의 검색 결과를 "빠르게' 리턴하기로 결정했다면,
평균 검색 요청의 응답시간에 대한 SLO는 100밀리초 이하로 설정할 수 있다.
적절한 SLO를 설정하는 것은 생각보다 복잡하다.
무엇보다 필요한 값을 항상 얻어낼 수가 없다. 예를 들어 외부에서 서비스로 유입되는 HTTP 요청의 경우, 기본적으로 초당 쿼리 수(Queries Per Second, QPS)라는 지표는 사용자가 서비스를 얼마나 사용하느냐에 따라 결정되므로 이 지표에 대한 SLO를 설정하는 것은 말이 되지 않는다.
반면, 요청당 평균 응답 시간을 100밀리초 이내로 달성하겠다는 목표는 설정할 수 있다. 또한 이런 목표를 설정하면 프런트엔트를 작성할 때 다양한 기법을 사용해 응답시간을 단축하려하거나 또는 응답 시간을 향상시킬 수 있는 장비를 구입하려 하게 될 것이다.(물론 100밀리초 대신 임의의 값을 사용할 수도 있지만 보통 빠른 응답 속도로 설정라기에는 적절한 값이다.
당연히 느린 것보다는 빠른 것이 좋을뿐더러 응답 시간이 어느 특정 값을 초과하게 되면 사용자들은 뒤도 돌아보지 않고 떠날 것이다.
좀 더 자세한 것은 논문을 참조하기 바란다.https://services.google.com/fh/files/blogs/google_delayexp.pdf
다시 말하지만, 이 두 SLI들(QPS와 응답 속도)이 뒷단에서는 서로 연관이 있을 수 있어서 처음보다는 그 차이가 더 작아질 수 있다. 즉, QPS가 높아지면 응답 속도 역시 느려지므로 일반적으로 부하가 한계치를 넘어서면 성능이 갑자기 뚝 떨어지는 현상이 발생하곤 한다.

SLO를 설정하고 고객에게 이를 공개하는 것은 거비스의 동작에 대한 예측을 가능하게 한다. 이런 전략을 통해 서비스 소유자들의 서비스가 느려지고 있다는 등의 근거 없는 불평을 줄일 수 있다. 명확한 SLO가 설정되어 있지 않다면 서비스를 디자인하고 운영하는 사람들의 생각과는 전혀 다른, 자신들이 희망한느 성능을 기대하곤 한다. 그리고 이렇게 생겨난 다양한 기대치 때문에 사용자가 실제 서비스가 제공할 수 있는 것 이상의 가용성을 기대해서 지나치게 서비스에 의존하는 현상(실제로 처비 서비스에서 이런 현상이 발생했었다.
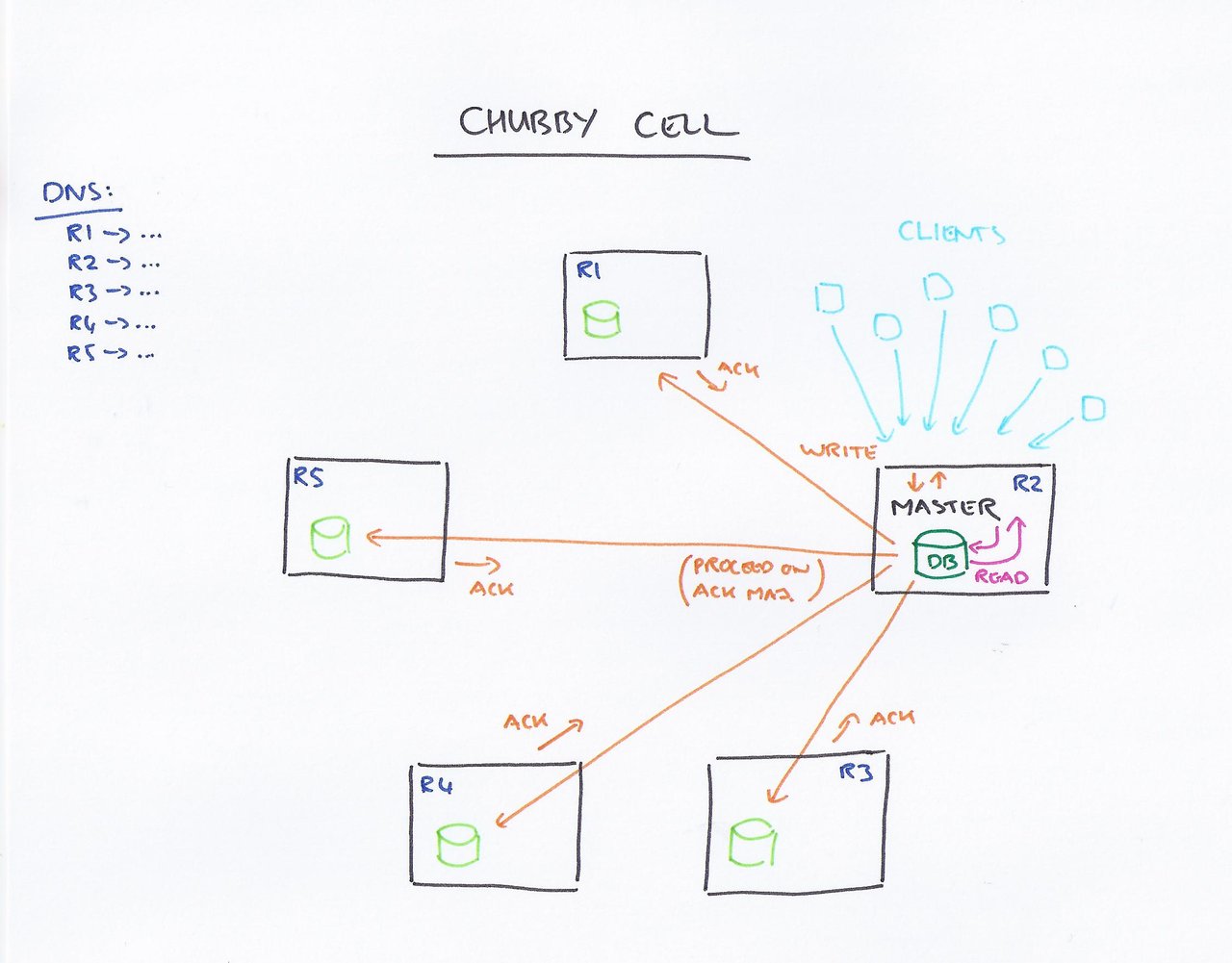
글로벌 처비(Chubby)의 예견된 장애처비(Chubby)는 느슨하게 연결된 분산 시스템을 위한 Google의 잠금 서비스다. 우리는 전 세계의 각 지역에 Chubby 인스턴스의 복제 노드를 분산해두었다. 시간이 흘러 우리는 처비의 글로벌 인스턴스가 지속적으로 서비스 장애를 일으켰으며, 그중 상당 부분이 최종 사용자에게 노출되었음을 발견했다.
실제로 글로벌 처비의 장애는 서비스 소유자들이 처비는 절대 다운되지 않을 것이라 생각하고 그에 대한 의존성을 추가하기 시작하면서 간헐적으로 발생한 것으로 밝혀졌다. 게다가 처비의 높은 신뢰성은 보안에 대한 잘못된 판단에도 일조했는데, 그 이유는 처비가 다운되면 서비스가 제대로 기능하지 않았지만 그런 일이 매우 드물게 발생했기 때문이다.

이에 대한 해결 방법 또한 흥미롭다. SRE는 글로벌 처비가 설정된 서비스 수준 목표를 달성하기는 했지만 대단하게 초과 달성하지는 못했다는 점을 확인했다. 그래서 매 분기별로 실제 장애 때문에 가용성이 목표치보다 떨어진 적이 없었으면 관리를 위한 서비스 중단을 시스템의 다운타임에 포함시켰다. 이런 방식으로 처비의 인스턴스가 추가되자마나 필요 이상으로 의존하게 되는 현상을 제거할 수 있었다. 그렇게 함으로써 서비스 소유자들은 분산 시스템의 실체를 좀 더 빨리 인식하고 고려 할 수 있게 되었다.
협약
SLA는 서비스 수준 협약(Service Level Agreement)의 약자로, SLO를 만족했을 경우(혹은 그렇지 못한 경우)의 댓가에 대한 사용자의 명시적 혹은 암묵적인 계약을 의미한다. 그댓가란 대부분 경제적인 것(환불이나 벌금 등)으로 대변되지만, 다른 형태로 나타나기도 한다. SLO와 SLA의 차이점을 쉽게 파악하려면 'SLO를 달성하지 못하면 어떻게 될 것인가?'를 생각해보면 된다. 이 질문에 대한 명확한 결론이 없는 경우라면 십중팔수 SLO라고 생각해도 무방하다.

- 사이트 신뢰성 엔지니어링, Site Reliability Engineering, 크리스 존스, 제니퍼 팻오프 -
Posted from my blog with SteemPress : http://internetplus.co.kr/wp/?p=498