Web-Scraping with Python if site is Dynamic - generated by javascript
Sometimes when web-scraping, simply feeding the html source code into BeautifulSoup will get what you want or need. That however is reliant on the fact that the site is static, meaning all the data is generated and processed before hand. Other sites will be dynamic (and I believe as time goes on, more and more sites will be dynamic to accommodate the user specific preferences and recommendations).
When you encounter a dynamic page, you will have to do a little investigative work to obtain the data, not too different than what you would do with a static site. Now one way to get the data is to simulate opening the browser, letting the data render, and then pull the html source code (this would be used with the Python package called Selenium). Now there is nothing wrong with doing that, and it follows the same techniques as parsing a static site. However, it does require the work and effort to iterate through the appropriate tags, and since the page is dynamic, the tags might not always be the same every time you open the page.
The other option is to try to see if you can find the source of the data directly and fetch it from there.
Now this method will not always work, and will not always be the same, but the general idea will usual follow:
1 When you right-click, you will want to Inspect the page:

2 This will open a side pane. You want to click on Network and click on XHR (note, you may need to re-load the page so those requests will be generated).
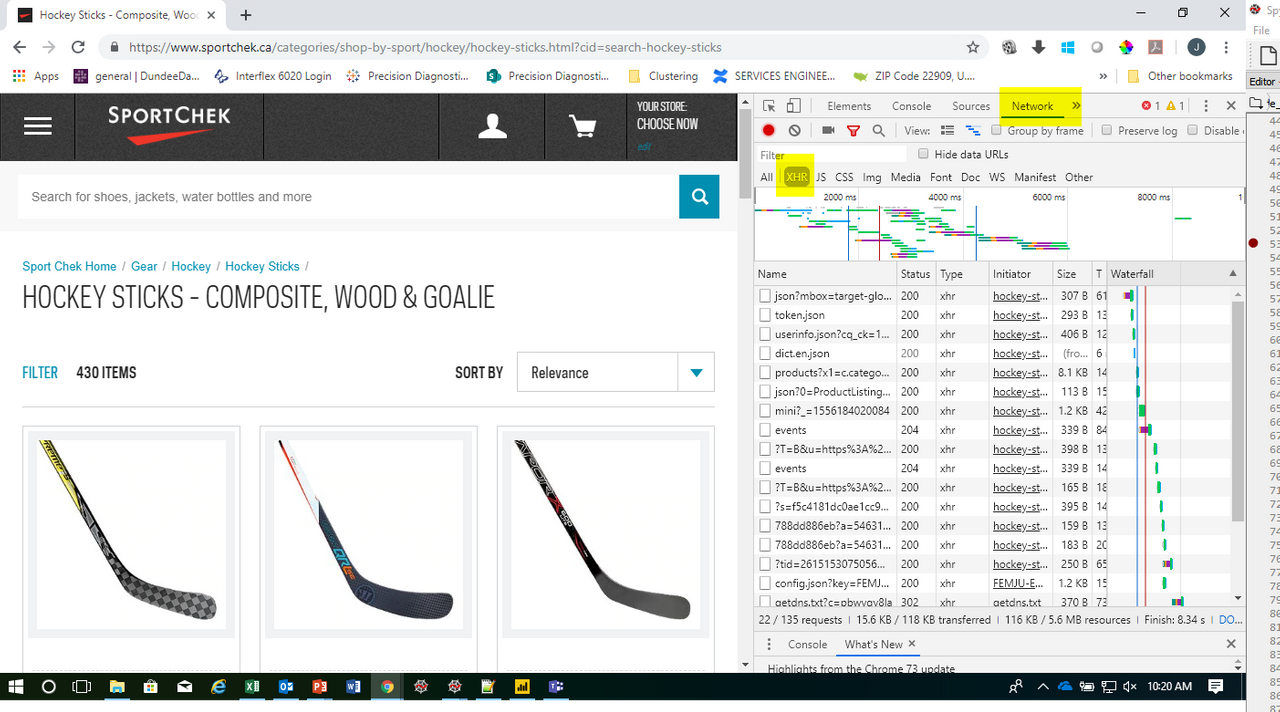
3 Start clicking through those requests that are rendered. You'll also need to be looking at Preview. In the preview, you'll see a variety of things. What you want to find is a json structure (basically a tree like structure). You can click on the little arrows to open/close the nested data. All you are doing is looking to see if you can find the data you are interested in obtaining. You won't ALWAYS find what you need, but I'd say more than half the time you'll be able to see it somewhere. If and when you find it, you can continue to the next part.

4 If I double click on the name of that request (under the Name column), a new tab will open to display what I would get in response to the request. You should see something like the image below. If not (possibly a blank screen or no data), you may need to find another way to get that data, as this will show you what the response will look like.

5 Ok, so it looks like you'll get a nice json structured response. So now you want to go to the Headers portion as that will get you the things you will need for the code:
1.You'll need the request url (up until the ?)
2.Whether it's a GET or POST request
3.Sometimes you'll need to use the User-Agent header (not always, but doesn't hurt to include)
4.Query parameters are sometimes needed
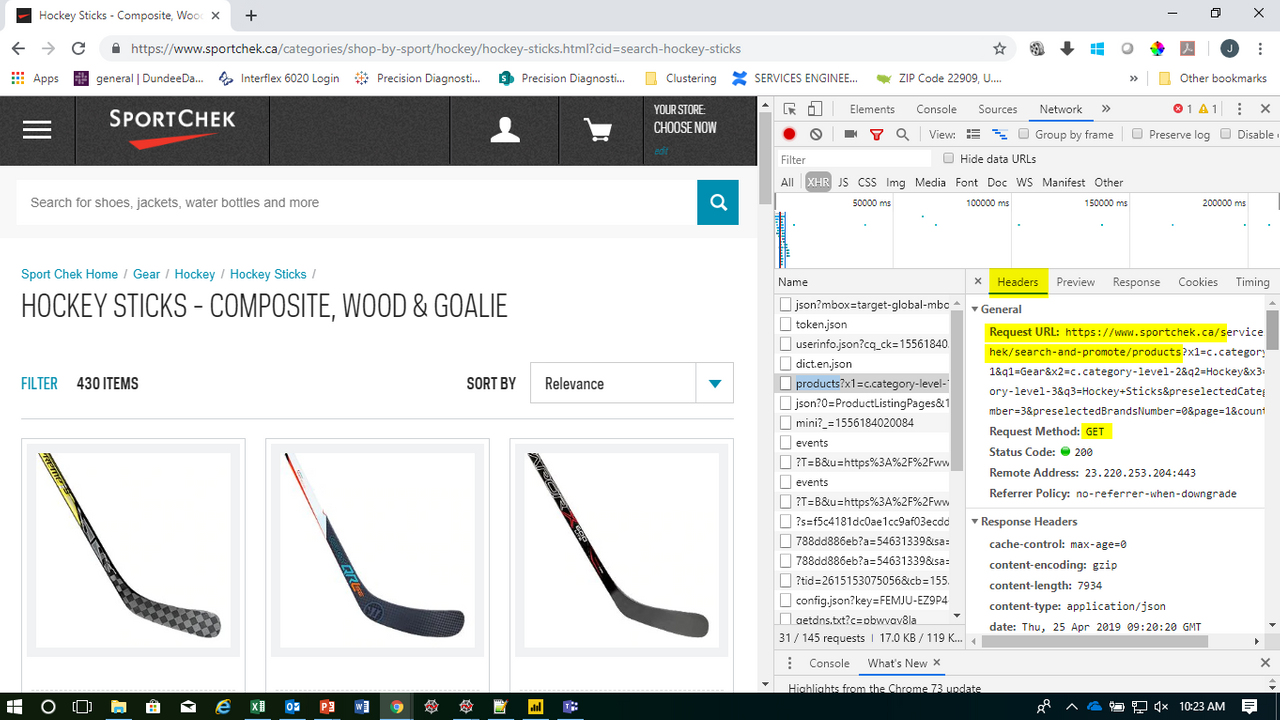

6 Now use that for your Python code. You'll have to play around with the query parameters sometimes. For instance, it was originally set at 16 items per page. I played around (I tried to change that to 99999), and noticed that it maxes out at 200 per page. I also was able to find the total number of items was 430. So I had to do a little extra work to get ALL the products (Ie. loop through the pages so that I could get all 430 products...but that's beyond the scope of the post.
url = 'https://www.sportchek.ca/services/sportchek/search-and-promote/products'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
payload = {
'x1': 'c.category-level-1',
'q1': 'Gear',
'x2': 'c.category-level-2',
'q2': 'Hockey',
'x3': 'c.category-level-3',
'q3': 'Hockey Sticks',
'preselectedCategoriesNumber': '3',
'preselectedBrandsNumber': '0',
'page': '1',
'count': '200'}
jsonData = requests.get(url, headers=headers, params=payload).json()
7 Now you have the data, it's just a matter of iterating through the structure to get what you want, or use pandas to dump into a dataframe, etc. All that stuff, is beyond the scope of this particular post, which is simply how to get that data
But just to give you the visual of that json structure
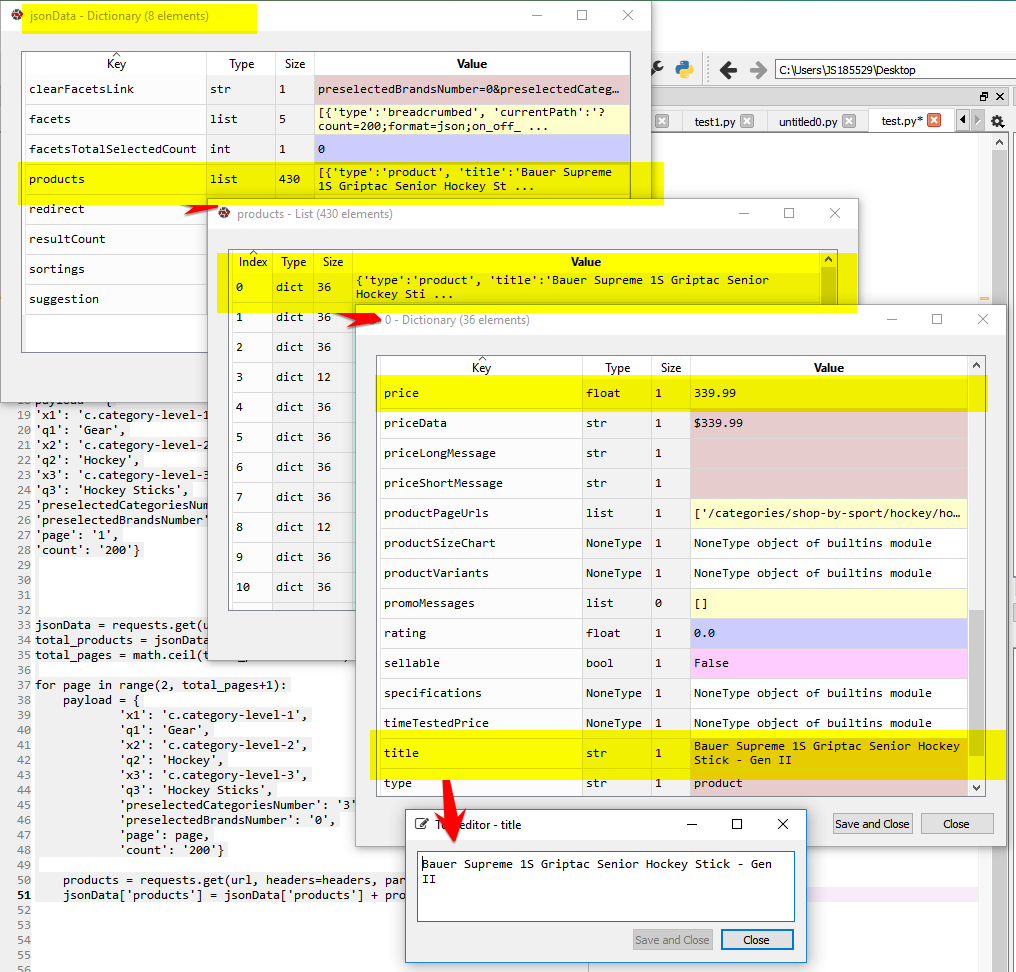
To get the specific price in the photo shown above:
jsonData['products'][0]['price']
to get the specific name/title of the the photo shown above:
jsonData['products'][0]['title']
If I want the NEXT price and title:
jsonData['products'][1]['price']
jsonData['products'][1]['title']
So as you can see, you'll be iterating through the list under the root jsonData['products'] to get each product information