Basics of linux operating system 101
![]()
Linux has gained a lot of popularity past decades, but its inner working can still remain obscure to many peoples, because it's not primarily based on graphic user interface, and is more often used via a terminal and command line, which can seem daunting to many users.
Basic architecture

As all modern operating system, linux is based on the different layers , which correspond to cpu memory protection implemented on intel cpu since i386, allowing for memory to be associated with diferent level of privilege, called 'rings'.
When a program is loaded in memory, the machine code will be loaded in memory associated with such rings, and most OS are architectured following this model.
- Ring 0 is kernel ring, it's where the code and data of the kernel will reside.
- Ring 1-2 is driver level, where device drivers or subsystem will reside.
- Ring 3 is application level, where user applications and data will reside.
Booting proccess

When the computer boot up, it will scan all the storage device for a bootable code marker, in the so called MBR for master boot record, and if one is found, it will load this code in memory and execute it.
On PC architecture, the amount of memory that this code can take is very limited, mostly limited to 512 bytes with traditional bios, and moreover, the intel cpu is booted in 16 bits so called 'real mode' , which allow for 1Mo of memory to be addressed.
It's why linux use a multi stage booting.
The first stage is loading the boot sector from the MBR. This code will mostly be used to load the second stage loader from the hard drive, or usb stick.
The second stage will most likely display a menu, and load the boot loader configuration, which contain the location of the kernel, the information to locate the root partition, and eventually some other parameters that can be needed to load and boot the kernel.
The second stage boot loader will then load the kernel from the configuration, and boot the system.
The most used bootloader is called grub.
When a new operating system is installed on the machine, grub will write the first stage boot loader in the target drive 'MBR' (master boot reccord), which contain the information needed to load and run the second stage boot loader (grub) as well as the location of the boot loader configuration file, and then it will finally load and boot the kernel from this configuration.
A ram disk image can also be loaded by the boot loader, because the kernel might need some basic files before the root partition is available. This ramdisk is often contained in a file called something like 'initrd.img', and can be passed by the boot loader as a kernel option.
Linux kernel
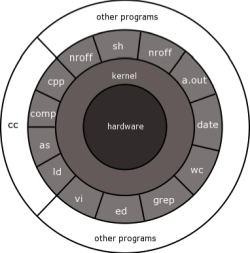
The kernel is the part of the operating system that deal with hardware, file system, and process. It's run in ring 0, and is the only piece of code that has access to the hardware and the process table.
It will detect the hardware, and load the required drivers, partition the available memory, and then mount the root partition, run the init process located on this root partition which will then initialize the rest of the system, such as network interface, and services, based on the configuration stored on the root partition.
C Library

(from wikipedia)
As the kernel internal structure is generally poorly documented, and subject to frequent update, most application will not use the kernel interface directly, but rather use the C standard library which contain the code to make the actual kernel calls.
The C library will be responsible for initializing the process, and provide standard API to access files, memory, spawn new process, and access system resources.
Filesystems
Root partition
On unix, the 'root partition' is the global file system, and all partitions and other devices are associated to a path in this root file system. There is only one root partition for an instance of the kernel, and all other partitions and devices are accessed via a location into this root partition.
The process of associating a filesystem to a path in the root filesystem is called 'mounting'.
Common directories
| Directory | Use |
|---|---|
| /bin | contain the base system commands |
| /boot | contain the files for the bootloader, as well as the kernel. |
| /lib | contain the base system libraries |
| /usr | contain the user applications. /usr/bin contains users applications executables. /usr/lib contains user libraries. |
| /etc | contain configurations files. /etc/fstab contain the list of filesystem mounted at boot. /etc/passwd contain a list of all users, with their uid,gid, and home directory. /etc/group contain a list of all groups and their associated gid. /etc/network/interfaces contain configuration for network interfaces. |
| /var | contain the data for system and services. /var/log contain system and services logs. |
| /root | home directories for root user |
| /home | contain the home directories for users |
| /dev | virtual file system containing kernel device entries |
| /proc | virtual file system containing kernel variables |
Filesystem attribute
Once a file system is mounted, all entries will be associated with an userid 'uid' also called the owner of the file, a group id, and a set of permission that define the access to the file.
The permission flag can grant read, write or execution access, to either :
- the owner of the file.
- users in the group associated with the file entry 'gid'.
- all others users.
It's generally represented by a 3 digit numbers, each number is a bit flags that represents the permission associated with the owner, users in the group, and all other users.
the flag is a 3 bit flag, which mean it can represent a number from 0 to 7, and flags can be combined to form the permission.
The bit flag are
| binary | decimal | meaning |
|---|---|---|
| 001 | 1 | execution |
| 010 | 2 | write |
| 100 | 4 | read |
So a read+write access is 4+2 = 6.
Execution flag for directory mean permission to open it and list its content.
To set the permission of a file as read and write for owner, read only for the user in the group and read only for all other users the permission flag yeld 644.
The first numbers is read/write for the owner, the second is read only for users in group, the third read only for all other users.
Root super user
All unix system have what is called a root super user, which is granted all permission by default. It's uid is always 0. When installing a new system, the installer will generally ask to create a new user, and use this user by default instead of the root user, which is considered safer, as all process run from root have all access to everything, this can lead to security flaw or critical mistakes.
Virtual file system
The big moto on linux is 'everything is a file', which mean all interactions with the hardware, process and everything else will be done through operation on a file descriptor.
In order to make this work, linux kernel make use of virtual file system, which are just like regular file system, except they don't correspond to file or directory on a partition, but represent a mapping of kernel ressources.
When the kernel boots, it will mount a certain numbers of these virtual file system, among which
the device filesystem, 'devfs' will be mounted on /dev, and will contain entries for all the hardware devices known to the kernel. For example '/dev/disk' will contain device entries for harddrives. Device names for harddrive can be pretty cryptic, but generally made of an id identifying the drive, followed by a number indicating the partition index on the drive. All operations to manipulate device will happen through operations on entries of the '/dev' virtual file system.
the 'procfs' will be mounted on /proc, and will contain entries for kernel variables, such as the process table keeping track of all processes running on the machines, and various infos about the system and hardware.
Those entries can be manipulated just like regular files on a filesystem, but instead of reading the data from a file on an harddrive or usb stick, it will read the data from kernel memory, or from an hardware device through the kernel.
Processes

Process are piece of code that are loaded in memory and allocated a certain amount of cpu ressource by the task manager. This process of allocating cpu ressources to a process is called scheduling.
Processes can also be considered as file, as on linux all processes will be associated with 3 file descriptors, 'stdin', 'stdout' and 'stderr' that will be used to send data to the process (stdin), read data from the process (stdout), monitor errors output (stderr).
Once the kernel boots up, new process can be created by loading an executable in memory, and adding the code entry point and other information into the kernel's process table. The kernel will then schedule its execution along side with the other process or tasks.
Each process contain at least the following information
- An unique identifier, called the 'pid'.
- An 'uid' as user id and 'gid' as group id, which will determine it's access to filesystem.
- The three files descriptors stdin, stdout, and stderr, which will be used to send and received data to/from it.
- Environment variables, which are values associated with a variable name that the process can access.
- A certain number of memory pages in the RAM that it can access .
Eventually if it's spawn from another process, it will also contain the id of the parent process.
As all operations on the system are handled through an access on entry of a filesystem, the uid and gid of the process will determine it's level of access to all ressources.
A process can also spawn another processes, which can inherits those informations from the parent process.
There are basically 3 kind of process that can be run on the systems
- Daemons will be process running in background, such as services.
- Console process such as command line or console applications which will be bound to a terminal with active monitoring of its stdout/stderr.
- Graphic process such as graphic application, which will be bound to a display on a graphic server, and a window manager.
Init process
Once the kernel bootup, it will run the 'init' process, which will scan the files with executable permission present in the directory '/etc/init.d', and execute them.
It generally include system daemons, script to configure network interfaces and bootstrap a terminal, or shell, which will most likely stand by waiting for a login , and then set its uid/gid according to the login informations for user to enter commands.
Terminal or shell

As all other process, it will have an stdin that will be used to read input from the keyboard or network, and stdout,which will be used to display it's output on the screen or send it to the network.
If the user use a local terminal, the commands from the keyboard are sent to the terminal, which will then execute the command according to it's own permission associated with the shell's uid and gid.
There are two kinds of commands that can be executed by the shell, either built in commands who are specific to the shell, or executable files that are located on a mounted filesystem.
Bultin commands are specific to each shells.
Such built in commands commonly include
- cd to change the current working directory.
- pwd print the current working directory.
- export display or set environment variables.
- unset clear an environment variable.
- echo output the specified text or environment variable.
- which used to find the location of an executable file on the filesystems.
A list of all environment variable can be seen by running the command 'export' without any argument.
For example, the content of the PATH variable used to automatically search for executable command is
echo $PATH
The home directory of the current user can be seen with
echo $HOME
Full list there
https://www.gnu.org/software/bash/manual/bashref.html#Shell-Builtin-Commands
Running new processes from the shell
Additionally to built in commands, the shell can be used to spawn new process from executable files.
When a new command is sent to the shell, it will look in a certain number of directories, contained in the environment variable 'PATH', to search for an executable file with execution permission granted to the shell's process uid/gid.
If the command start with a '/', it will try to load and execute the file at the specified path.
If the command start with a '~', it will try to load and execute the file at the specified path relative to user's home directory of the shell's uid.
To run a file in the current working directory, need to use './exe_file'.
Basics commands
Core system commands
| command | action |
|---|---|
| whoami | display the current user |
| su _user_ | spawn a new shell as child process with the uid of the specified user. |
| sudo _command_ | execute the specified command as root. |
| mount _/dev/disk/XXX_ _/mnt/path_ | mount the selected partition to the specified mount point. if run with no argument, show all the file systems currently mounted on the system. |
| umount _/mnt/path_ or _dev/disk/XXX_ | un mount the filesystem. |
| exit | close the current shell instance, and go back to the parent process. |
| ls _options_ _directory_ | list files in the current working directory or the path given as argument. ls -l _/path_ output all informations from the entries. ls -a _/path_ list also hidden files ( starting with a _._ .) in the directory |
| mkdir _directory_ | create the given directory |
| rmdir _directory_ | remove the given empty directory |
| rm _file_ | remove the specified file from the filesystem. rm -rf _directory_ remove the directory and all its files and subdirectories (use with caution :P) |
| ln _file1_ _file2_ | Create a link to file1 in the path specified as file2. The flag -s can be used to create a symlink |
| cp _file1_ _file2_ | copy file1 to file2. cp -r copy directory and subdirectories. |
| mv _file1_ _file2_ | move file1 to file2 |
| ps | list the running process. ps -aux list all the active processes with more informations. |
| top | run a console application to list all active processes |
| chown _user_ _file_ | change the owner of the specified file. chmod -R _user_ _/path_ change the owner for all entries in the directory and subdirectory |
| chgrp _group_ _file_ | change the group of the specified file. chgrp -R _/path_ change the group for all entries in the directory and subdirectory |
| chmod _permission flag_ _file_ | change the permission flag of the specified file |
| cat _file_ | output the content of the file given as argument |
| head _file_ | output the first lines of the specified file |
| tail _file_ | output the last lines of the specified file |
| grep | search for a given string in the input |
| useradd | a new user to the system |
| usermod _user_ _options_ | change attribute of specified user. |
| find _directory_ _options_ | output a list of file in the given directory |
| passwd _user_ | change the password of specified user |
| man _command_ | display the manual page for the given command |
| kill _pid_ | terminate the process with the specified pid |
| killall _process name_ | terminate all the processes matching the given name |
| ifconfig _network interface_ up|down | if run without argument, list all the active network interfaces. ifconfig eth0 down deactivate the network interface 'eth0'. ifconfig wlan0 up activate the network interface 'wlan0' using the configuration in /etc/network/interfaces. |
All commands can be run with optional switch, by adding them to the command line, that will define some option on the output or affect the way the operation is processed.
Running command with the --help switch generally gives details about the command and the different options.
The default behavior when running an executable from the shell is to display the output on the console, but it can also be 'piped' as the input of another process with the character '|', redirected to a file using the character '>', or append to a file using the characters '>>'.
When the output of a process is piped to the command 'xargs', each line of the output can be used as an argument for another command.
For example, to find a given word in all files from a directory, can use
find /path/to/directory -type f | xargs grep -n 'word'
The switch -type f mean find will only output files, -type d can be used to list only directories.
The switch -n for grep will display the line number where the word is found in the input file.
Command line utilities
The following are not always installed by default, they might need to install specific package
| command | description | package |
|---|---|---|
| nano _file_ | basic text editor. basic commands : ctrl+o to save the opened file ctrl+w to search inside the opened file ctrl+x to quit | nano |
| unzip _file.zip_ | unzip the zip file in the current directory | unzip |
| zip _file.zip_ _path/*_ | add the files from the directory into the zip file. zip -r add all files and subdirectories to the zip | zip |
| gzip _file_ | compress a single file to _file.gz_ gzip -d file.gz decompress the gzip file. | gzip |
| tar -cf _file.tar_ _/path_ | archive all files from path into file.tar without compression. tar -czf then compress the .tar file using gzip. tar -xf _file.tar_ extract the file from the .tar file in current directory. tar -xzf file.tar.gz uncompress the tar file and exctract the files in current direcotry | tar |
Shell scripts
Most shell also contains a basic script engine, which can be used to parse environment variable, spawn some processes and do some conditional execution based on process return code or output.
Those shell script generally are in files with the .sh extension, and start with the line #!/bin/bash or #!/bin/sh to indicate the shell program used to execute them.
Daemon and services
Daemon are process that will be run as background tasks.
Unlike commands run from the console they will detach themselves from the shell, change their uid and gid to a specific user set in the daemon configuration, and their output will be redirected to a log file, usually either in /var/log, or in a subdirectory of the user's home directory.
The script to run daemon are usually located in /etc/init.d, and their configuration files is usually somewhere in the /etc directory.
Then are also often associated with a port and can serve network request directed to that port.
Their uid and gid define their level of acess to system resources.
Common daemon are
- Apache, HTTP server
- NGix HTTP server
- mysql database server
- sshd remote terminal server
- pureftp FTP server
- proftp FTP server
- exim SMTP mail server
- bitcoind bitcoin node
Package system
Most linux distribution are built up uppon a package system, which contain all the different files that can be installed, removed or updated on the system.
The package system is made of 3 components
- The package repository, which can be located on the installtion cd/flash drive or on a remote server. It contain the list of all packages that can be installed on the system.
- The local package cache, generally located in /var, contain a summary of the repository, as well as all the package installed on the local system.
- The package themselves, who are essentially like a self installer zip, it contain files and installation script to install the package on the system.
Different linux distributions use different repositories, with different set of packages, and it's generally recommanded to stick to a repository compatible with the distribution being installed.
Distributions can also have different repositories such as 'stable' , 'testing' to store more recent versions of the packages, as well as sub repositories for sources packages, or optional packages that are not integrated by default in the main distribution.
There are two commonly used package system on linux, the debian system, and redhat system.
They both contain command to configure repositories, browse these repositories, and manage locally installed packages, as well as the command to deal with the installed package files themselves.
Debian packages
![]()
On debian based system, such as debian or ubuntu, the command to manage repository are apt-get, apt-cache, and others starting with apt-, the command to manipulate package files is dpkg.
The repositories that apt- commands will use are configured via the /etc/apt/sources.list file.
apt-get update will update the local cache with available package.
apt-cache search keywords can be used to list the package in the cache associated with the keywords.
apt-get install package can be used to download and install a package from the repository.
apt-get remove package will uninstall the package.
dpkg -l can be used to list all the package installed on the system.
dpkg -L package can be used to list all the files contained in the package installed on the system.
dpkg -S file can be used to find which package contain the specified file.
Redhat packages
On redhat based system, such as redhat, centos, fedora, the command to manage repository is yum, the command to mannage package files is rpm.
Installation on Mac OS using Virtual Box
The video show how to setup ubuntu server inside of virtual box. Virtual box is a convenient way to quickly install guest operating system, the interface is the same on every operating system.
VirtualBox can be downloaded here https://www.virtualbox.org/
The Ubuntu server iso file can be downloaded there https://www.ubuntu.com/download/server
I added the commands as subtitles in the video.
If it's installed on a physical machine, the procedure is roughly the same, and what is displayed in the virtual box window will be what is displayed on the screen, and you can connect the service using the machine's IP and the default ports.
If you use linux from a VPS or dedicated server, you can skip the first part, and skip to 22:00, you just have to select ubuntu 16 64 bit when setting up the box from the hoster panel, and then remote shell software like putty on windows can be used to connect the box directly using the user and password given by the hoster.
Most FTP and shell client will also support sftp transfer using the shell server port, to transfer files on the machine.
If the VPS or dedicated server has a root access, the root user can be used, the password is given in the hoster panel, and then you can skip the 'sudo' prefix on commands.
If you use a server without root access, it will generally have phpmyadmin already installed, and you can access it through the admin panel of the hoster, and most likely the database are created and configured through the admin panel too.
I will also try to complete with more informations or clarify certain things if they are not clear enough or lacking details.
Congratulations @h0bby1! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPMy ex introduced me to Linux perhaps five years ago, and I was astounded by it. A software built entirely by the people for the people. Awesome!!
I'm not sure it's really that much the case anymore that linux is built by people for people, maybe it's still the case for debian as they are hard lined on the free software license issue, but most distribution are becoming more corporate, like firefox, and lot of development is paid by companies for the industry :)
But it still remain open source, and all the code can be re used freely or modified to build other open source software, or to patch bugs, or customize some part of the code, as long as all modification and distribution based on gpl code remain gpl and open source too.
Thanks for clarifying. :)
Great blog, thank you for sharing @h0
sorry my question. but this is only diagram or indeed. is a circular onion estructure. coz old midia is circular vinil disc. always i wish know how one disc CD or tape ou LP in rotation can run a program in real world
The circular diagram is to illustrate ring architecture, its not representing physical media, but how different layer of software interact from the most privilegied at the center, like the kernel who has all access to everything, to least privilegied like user application on the outer layer, whose access is restricted at ring boundaries.
For programs stored on media like cd or dvd, programs are just regular data, as long as the kernel can mount the filesystem, and read the data from the different files stored on it, it can load the code and other files from it, and execute them.
I'll probably make another post to explain basics of unix C programing, file and network access, and executable file as well as libraries latter to explain better the ring architecture.
But the ring structure is not especially related to physical location of the data, the kernel can decide arbitrarily using cpu memory unit which pages of memory can be accessed by a process.
thanks. i rely want undestand how a program run in a disc or tape running
Basically the kernel load the exe from the filesystem to memory and create a process out of it.
Exe file contain different sections, at least one code section and a data section, as well as an exported entry point which tell the loader where the code start inside of the code section.
The kernel loads each sections in memory, and resolve reference to the data used by the code, and insert the program in the process table.
But ill make a more in depth post for this.
Thank you for this. I am going to try to set this up on an old laptop.
Following for updates!
I installed the stuff to make the video to setup web server with ubuntu today, ill try to make the video tomorow :)
Thank you!
I will sure to watch.
Once you install on your laptop and try out, get a little vi tutorial from the net and study it - you will be amazed, vi can do for last 40 years what word still can't do today - for example putting a word or ; at the end of each line... psst psst - warning - u will fall in love with linux! :) - I am a linux/unix user for last 20 years...
I'm not big fan of vi, but i know people who know it well can do lot of things with it :)
I prefer to edit the code on windows, with good ide, and tools, debugers, code analyzers etc, and only compile on linux.
Generally i use a shared drive on linux, and edit the files via windows or mac.
Or i use nano for small edits on configuration files.
Congratulations @h0bby1! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPI think Linux is great operating system for every possible use cases EXCEPT personal use ( even though I installed Linux for my parents and they loved it! ). Today, many Linux distros are click-based and have great looking GUIs, but it's not used with GUI because most of Linux users are programmers and IT guys.
All in all, situation today is great, there are number of commercial and open source solutions and operating systems with all their pros and cons and they need each other to create better hardware and software.
I mostly use linux for servers, like for http, sql,mail, nas, or services that are acessed via network.
For running server side of blockchain nodes too .
Lack of good drivers and sdk make it not that great for desktop and multimedia, unless you are allegic to windows or dont want to pay licence or use cracked apps.
But for server app its still good, for everything like process, files, network and services it still has advantages over windows.
I mostly make this blog for those who want to install things on vfs or setup home servers to install node.js or blockchain nodes, or web servers, to know the basics.
When the video will be done, i'll basic basic tuto to explain unix C programing to make simple daemons or process on linux, and continue the serie on php/js.
But its not especially good for multimedia , for desktop can be ok if its to do mail and browse internet, but not much more, even if its always possible to do things with wine or virtual box, or for basic graphic applications.
Actually I find it great for personal use, not only for my own use but also for a friend who is way too thick to ever run Windows without daily hand holding.
Nor have I ever had any problem with drivers, the kernel, like OsX automatically takes care of the issue. There is one caveat about that though, you do need to check for compatibility before buying peripherals. I will simplify that issue, Brother and HP printers are usually fine and Cannon scanners too.
@rlp1938, I think @h0bby1 makes a point about multimedia. It's true that Linux and OsX take care of drivers, but open source drivers which aren't always good for 3d rendering, or games and stuff like that. When you have graphic cards from AMD or nVidia, it's not always easy to install their drivers and they don't always work. I'm glad that there are people that use Linux for personal use :)
Congratulations @h0bby1! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPI made first try for the video, but didnt get it right yet, its the first time i do video tutorial :)
but normally now i found the good soft to make screen video capture with audio, and i have the basics setup prepared, so i will make the video tomorow.
I feel like I time traveled 15+ years back sitting in my IT class