[논문 소개] Jointly Optimize Data Augmentation and Network Training: Adversarial Data Augmentation in Human Pose Estimation
- 논문 정보
- 논문 제목: Jointly Optimize Data Augmentation and Network Training: Adversarial Data Augmentation in Human Pose Estimation
- 논문 링크: https://arxiv.org/abs/1805.09707
- 학회 정보: CVPR 2018
오늘 소개시켜드릴 논문은 "Jointly Optimize Data Augmentation and Network Training: Adversarial Data Augmentation in Human Pose Estimation" (https://arxiv.org/abs/1805.09707) 입니다. 올해 CVPR에 나올 논문입니다.
제목에서 볼 수 있듯이 Data augmentation에 관련된 논문입니다. 최근들어 모델을 벗어나 data augmentation 관련 논문이 자주 나오고 관심을 가지고 있는데 이 논문도 그런 방향을 가지고 있는거 같습니다. 최근 "AutoAugment: Learning Augmentation Policies from Data" (https://arxiv.org/pdf/1805.09501.pdf)와 같이 augmentation을 자동화하려고 하고 그것에 RL이라들지 다양한 접근 방법을 시도하고 있습니다. 그만큼 data augmentation은 학습 과정에서 매력적인 방법이나 그 방식이 의외로 발전이 더딘 면이 없지 않았습니다.
오늘 소개시켜 드릴 논문은 data augmentation의 문제중 모델 학습과 data augmentation의 최적화가 따로 노는 문제점을 해결하는데에 목적을 가지고 있습니다. 'Jointly Optimize'라고 표현되어 있으니 학습의 loss 함수에 data augmentation에 관련된 텀이 포함될거 같은데.... 제목에 'Adversarial'이라고 똭 써놨습니다. 그러니 adversarial training 방식으로 고려하는 loss가 증가하겠거니 하고 예측이 가능합니다.

논문의 대략적인 내용을 담은 그림에서 그런 내용이 다 나옵니다. 그리고 여기서 optimize라고 표현된 이유이기도 한데, 보는 것과 같이 새로운 augmentation을 찾아내는게 아니라 정해진 augmentation의 파라미터를 최적화하는 방식입니다. 또한, 그 과정은 adversarial augmentation이란 이름으로 학습 과정과 같이 학습을 시킨다는 것입니다.
자.. 그럼 그걸 어떻게 하냐인데.. 문제가 있습니다. augmentation의 최적화 방향입니다. 이게 좋냐, 나쁘냐 얼마나 좋냐. 이 기준이 있어야 loss에 추가할 방법이 있을건데 이 논문에서는 그것을 random augmentation과의 비교로 해결했습니다.
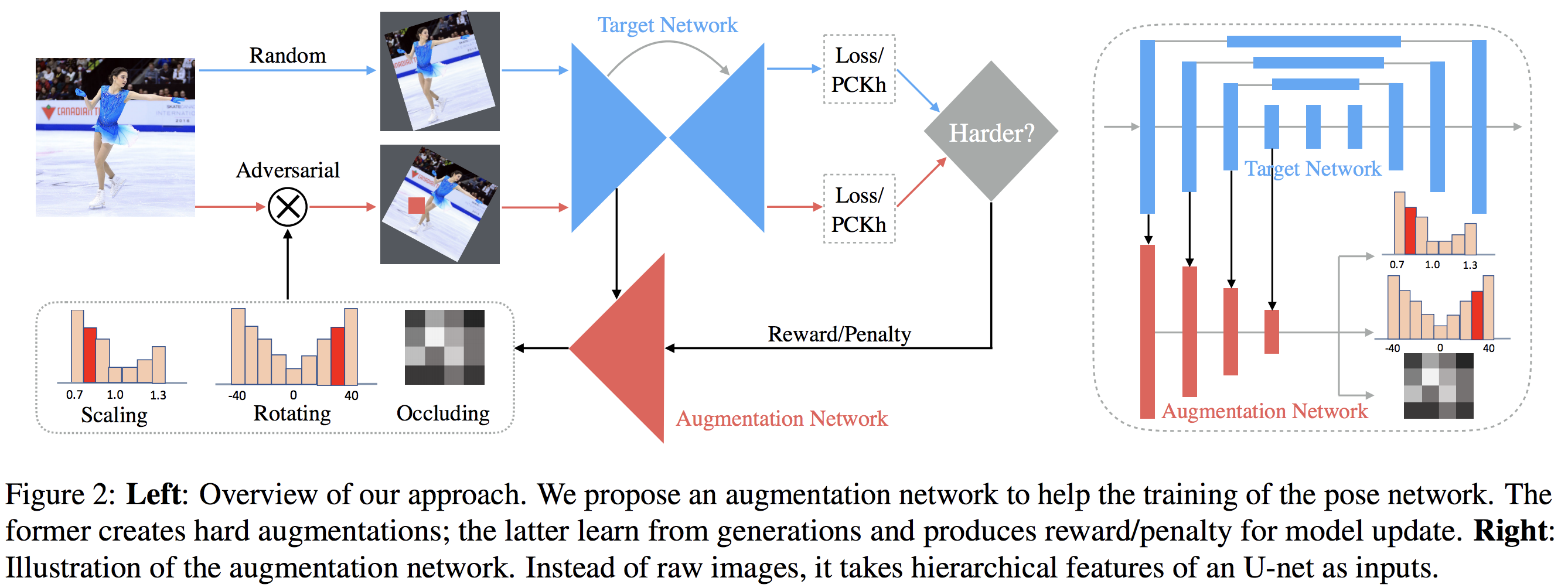
그러니깐 random augmentation한거보다 최대한 더 어렵게 하는 것을 방향으로 설정했습니다. 그래서 아래와 같이 수식이 나옵니다.

최대한 더 random augmentation보다 어렵게 만드는 방향으로 최적화해 나갑니다. 그리고 adversarial 방식이기 때문에 Discrimination도 필요하죠. 그건 당연히 아래와 같이 설정합니다.

그러니깐.. 정리하면 Discrimination path에서는 학습이 잘 되어 포즈를 더 정확히 측정하도록 하고, Generation path에서는 random augmentation보다 최대한 어렵게 augmentation을 generation하는 방향으로 학습을 합니다.

문제를 잘 넣은 모양세입니다. 위 그림과 같이 논문에서는 scaling, rotation, occlusion에 대해서 실험을 하였습니다. 결과적으로 전체적으로 random augmentation보다 좋은 성능을 보이고 있습니다. 음.. 드라마틱하게 좋아지진 않아도, 효율적으로 augmentation을 한다는 느낌은 드네요.

물론 한계는 있지만 augmentation이 모델과 별개로 학습되고 선별되는 과정에 대해 많은 분들이 불편해 하고 있었는데, 그 부분에 대해서 RL, adversarial training 등 다양한 시도를 통해 해결하려고 하는거 같아 기대가 되네요.