Cosa è Internet?
Salve a tutti Steemians; rieccoci col terzo articolo riguardante Internet e tutto ciò che si nasconde dietro di esso. Se vi siete persi gli articoli precedenti, vi invito a recuperarli e vi lascio il link qui presente del precedente articolo: Cosa è Internet?. Oggi faremo un altro passo per addentrarci in Internet, spero sia di vostro gradimento e vi auguro buona lettura.
Cosa è il core di Internet?
Il cuore di Internet è formato da una rete di router collegati tra loro. Essi consentono la trasmissione di messaggi da un host all'altro. I messaggi vengono, però, suddivisi in parti più piccole, i pacchetti, che viaggiano in maniera indipendente gli uni dagli altri. Ogni pacchetto ha un'intestazione dove vi sono tutte le informazioni riguardo il mittente ed il destinatario (specialmente l'indirizzo). Per similitudine potremmo riferirci ad un nostro pacco da inviare attraverso l'agenzia postale; ebbene, affinchè esso arrivi a destinazione, sarà necessario che il postino venga a sapere dell'indirizzo sia nostro, da cui recuperare il pacco, sia del nostro amico, a cui recapitarlo. Quando un router riceve, di fatto, un pacchetto legge l'indirizzo di destinazione e lo instrada per la via meno trafficata. Poichè i messaggi viaggiano in cavi, sfruttano la capacità trasmissiva del mezzo (doppino telefonico, cavo coassiale, fibra ecc.).
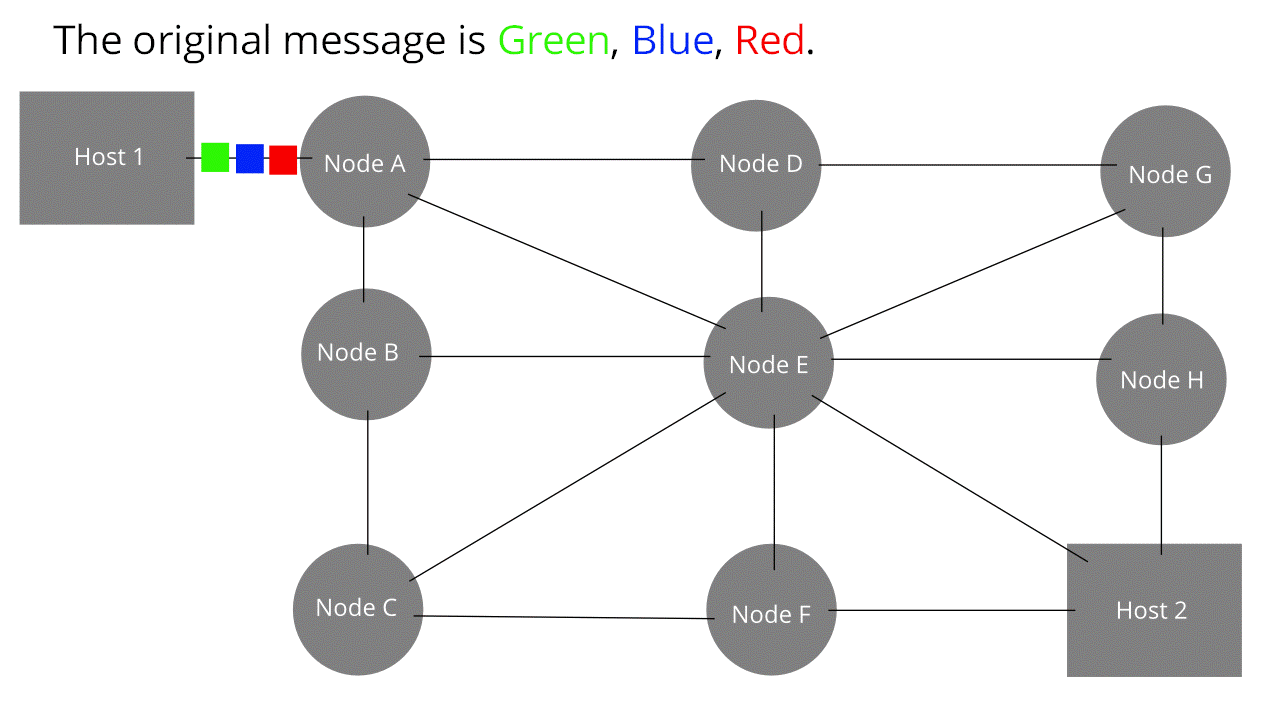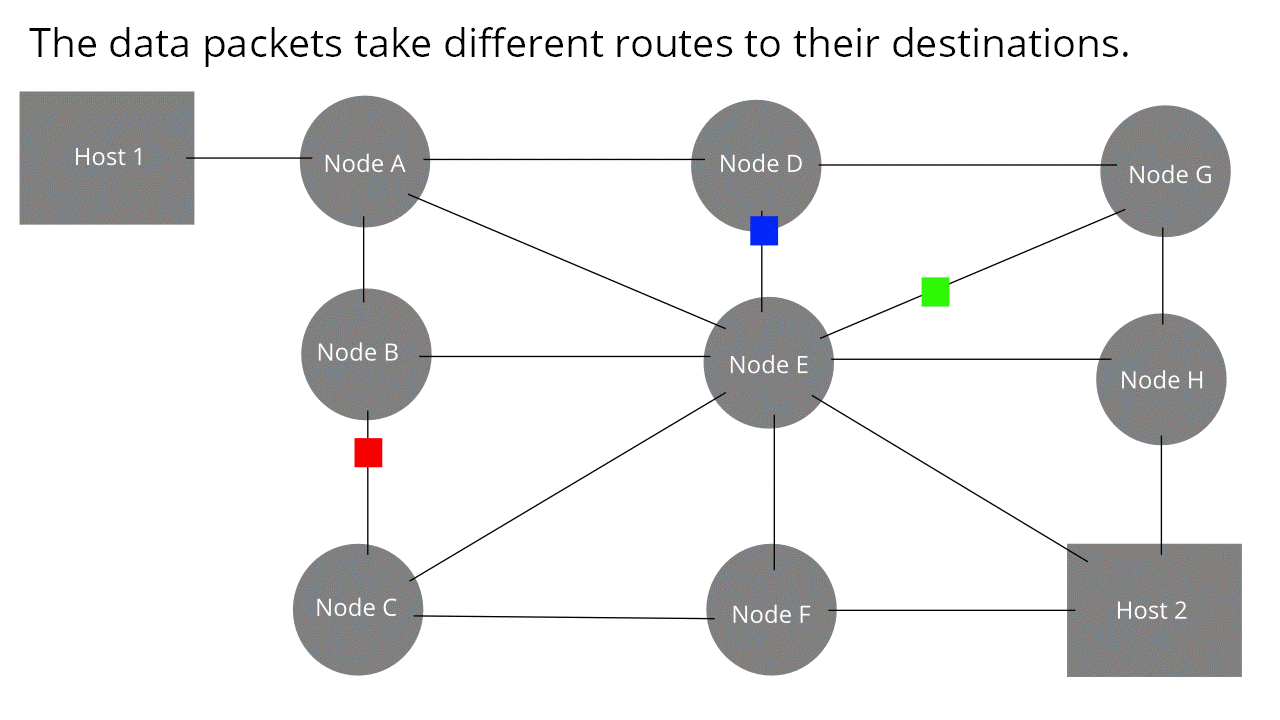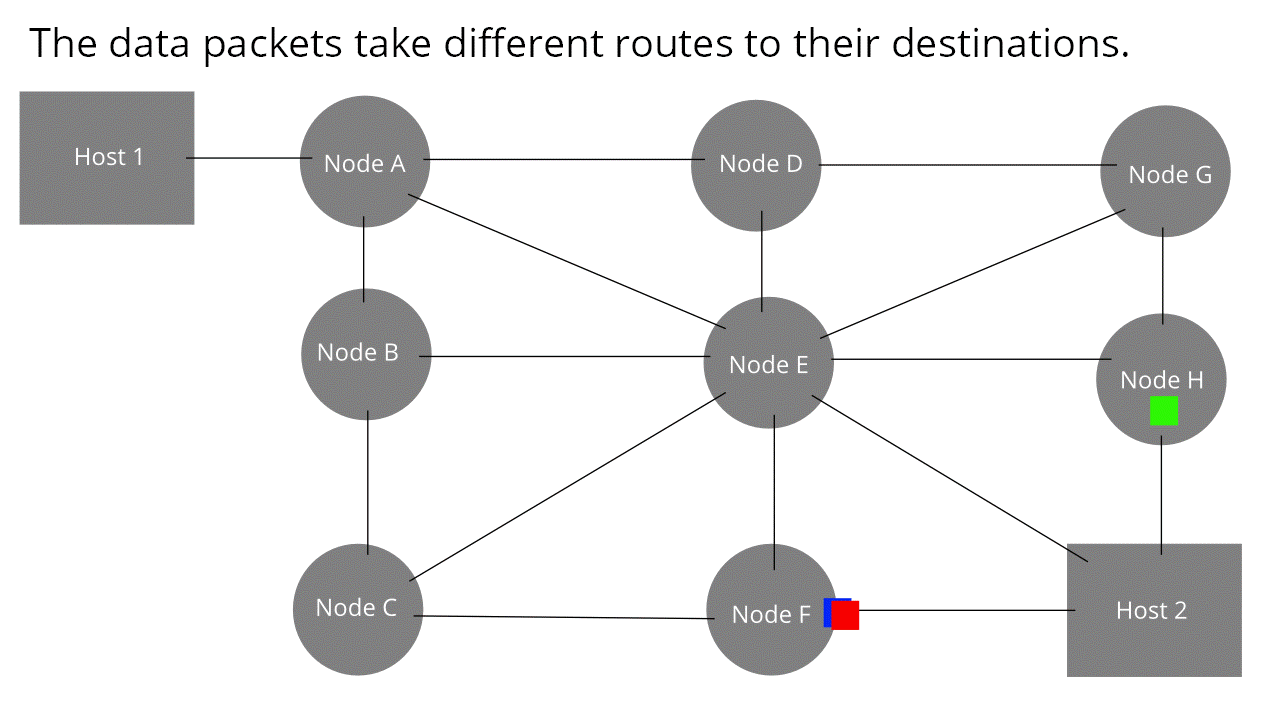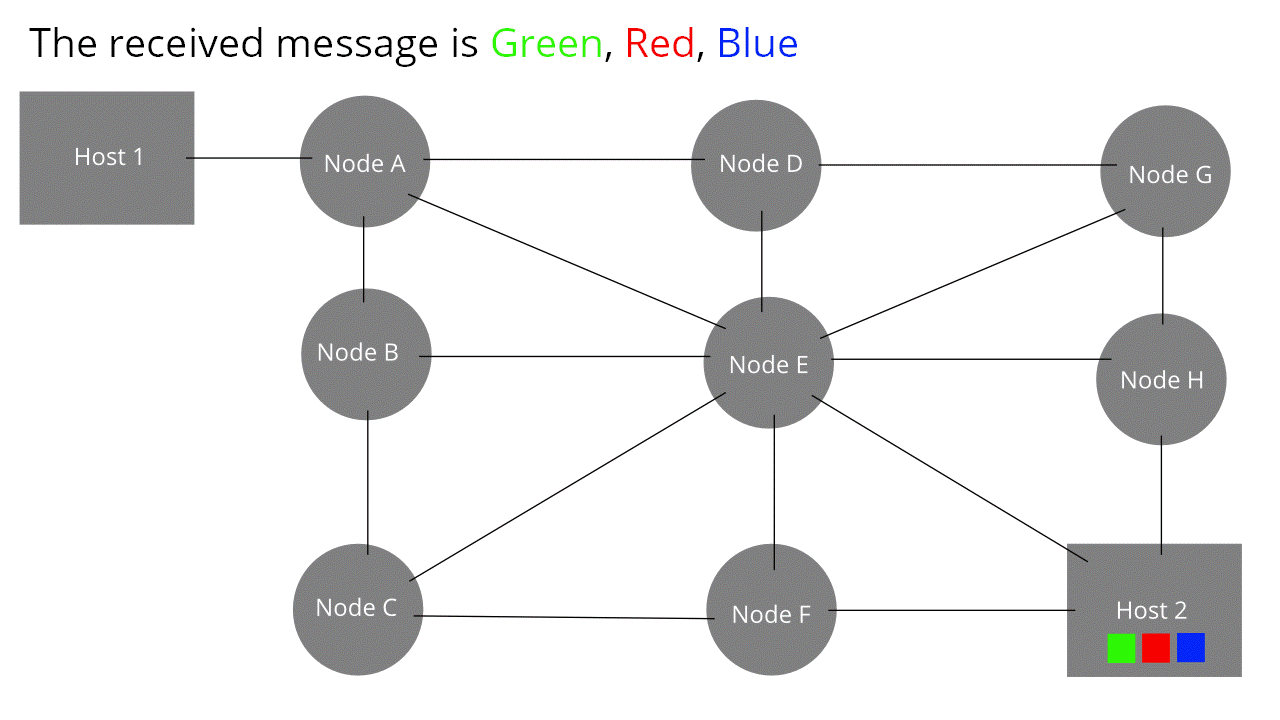
{kind=link}
CC0 Creative Commons
L'Internet ideale, che tutti vorremmo, dovrebbe consentire l'invio di qualsiasi quantità di dati senza ritardi e senza perdite. Purtroppo però vi sono le leggi fisiche che limitano il throughput, ovvero quanta informazione spediamo nel cavo per unità di tempo. Vi sono infatti dei ritardi e alcuni pacchetti potrebbero anche andare persi per la rete. Tra i ritardi si annoverano:
- processing delay delab, ritardo di elaborazione, ovvero il tempo richiesto dal router per esaminare l'intestazione del pacchetto e per determinare dove dirigerlo. Questo ritardo è dovuto al fatto che i router presentano delle tabelle di inoltro locale secondo cui instradano i pacchetti. Di fatti all'interno della tabella si mostra il next-hop, ovvero il prossimo router a cui mandare il messaggio per "avvicinarsi" al destinatario. Ebbene si, i nostri messaggi arrivano step by step, passo dopo passo, da un router all'altro fino al destinatario. Purtroppo però questa decisione richiede tempo perchè il router deve leggere l'intestazione, l'indirizzo a cui il pacco deve andare, scorrere la tabella ed individuare il next-hop che risulta essere più vicino alla destinazione. Ciò risulta efficiente come se fosse uno smistamento postale e purtroppo può comunque sbagliare come del resto fanno gli uomini;
- queueing delay dacc, ritardo di accodamento, ovvero il tempo di attesa di trasmissione sul collegamento. Poichè la maggior parte dei router usa una trasmissione detta store and forward: si riceve prima l'intero pacchetto per poi trasmettere il primo bit sul collegamento scelto in uscita. Il ritardo dipende dal numero di pacchetti arrivati prima del nostro, accodati in un buffer d'uscita alla linea corrispondente, detta anche coda di output, come la fila davanti all'entrata di un concerto.
Se la coda è vuota allora questo ritardo è nullo, sarà invece lungo qualora vi sarà traffico. In particolare in caso di traffico, il buffer si potrebbe riempire ed i pacchetti che "arrivano tardi" verranno buttati, in questo caso si parla di packet loss o anche perdita dei pacchetti, oppure potrà essere scelto uno dei pacchetti presenti nel buffer che risulta meno importante e al suo posto verrà memorizzato il neo arrivato. Nel primo caso si parla di coda FIFO (FIFO sta per first in first out, ovvero il primo ad arrivare è il primo ad andarsene), nel secondo di coda a priorità, già...anche in rete alcune volte non c'è meritocrazia; - transmission delay dtrasm, ritardo di trasmissione, il pacchetto viene trasmesso solo dopo la trasmissione di quelli che lo precedono nella coda. Se il pacchetto è lungo L bits e la capacità trasmissiva R bps (bits per second), allora la latenza di trasmissione è L/R secondi, ovvero questo è il tempo per trasmettere tutto il messaggio da un router ad un altro. Su ogni linea quindi la trasmissione sarà L/R, inoltre se consideriamo N linee tra noi ed il destinatario, possiamo definire una latenza generica che è NxL/R, anche definita come distanza end-to-end (senza tenere contro degli altri ritardi). In linea generale dipende dalla lunghezza del pacchetto e dalla larghezza di banda;
- propagation delay dprop, ritardo di propagazione, il bit viaggia alla velocità di propagazione del collegamento che dipende dal mezzo fisico. Il ritardo è in generale calcolabile come distanza/velocità;
Il ritardo end-to-end complessivo è la somma di questi ritardi per il numero di router tra noi ed il destinatario:
dend-to-end = Nrouter x (delab + dtrasm + dacc + dprop)

CC0 Creative Commons
La comunicazione tra sorgente e destinatario determina la creazione di un canale fisico, detto circuito fisico, nella rete; ciò è tipico della rete telefonica che è a commutazione di circuito, ovvero le risorse vengono riservate per la durata della comunicazione garantendo una prestazione maggiore perchè i pacchetti non subiscono ritardi, però si paga per il tempo di occupazione delle risorse. Inoltre vi è un software per la creazione del circuito che è molto complesso in quanto deve trovare il percorso "ottimo" e le risorse libere da assegnare. Di fatti, per esempio, una telefonata crea un canale di comunicazione tra noi ed il destinatario della chiamata e paghiamo per il tempo che spendiamo a parlare, occupando appunto un circuito. Per la telefonia, in particolare, la parte iniziale dei nostri numeri è identificativo della zona dove ci troviamo; ad esempio un numero con 00 iniziale indica una chiamata oltre la nazione in cui ci si trova. La trasmissione della voce, poi, è regolare e continua.
Ricapitolando, quindi, per la telefonia, la commutazione di circuito ha come PRO:
- Garantisce ottime prestazioni;
- Presenta traffico regolare;
come CONTRO:
- Riserva banda anche se non è usata e la si paga per il tempo d'utilizzo (anche non usarla è considerato come utilizzo);
- Presenta dei costi per creare il circuito;
- Risulta complesso da implementare;
Per i computer ciò avviene diversamente, infatti i dati vengono trasmessi a raffica attraverso la commutazione di pacchetto, con un alternanza tra picchi e silenzi. Per identificare un computer si parla di indirizzi a 32 bits, detti indirizzi IP suddivisi di 8 in 8 separati da punti. Alcuni esempi sono 0.0.0.0 oppure 192.168.1.1; gli indirizzi IP come per i numeri di cellulare sono "gerarchici", ovvero da sinistra verso destra descrivono zone geografiche più ampie fino ad arrivare a zone più ristrette. Di fatti il router, quando deve leggere l'intestazione del pacchetto appena arrivato, da sinistra a destra legge l'indirizzo IP del destinatario. Nel caso di Internet non è possibile una connessione diretta tra due utenti e tanto meno far pagare entrambi per il tempo con cui occupano le risorse. A questo proposito si implementano diverse tipologie di circuito, detto multiplexing, ovvero si divide la banda tra più circuiti:
Multiplexing a divisione di frequenza, FDM o anche frequency division multiplexing, usato per TV, DSL e segnali analogici;
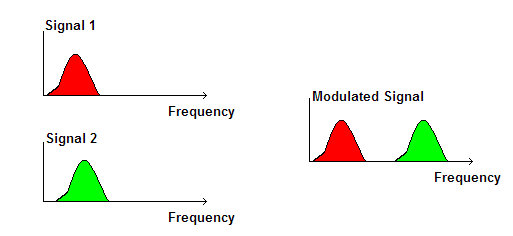
CC0 Creative CommonsMultiplexing a divisione di tempo, TDM o time division multiplexing, usato per trasmettere dati e segnali digitali;
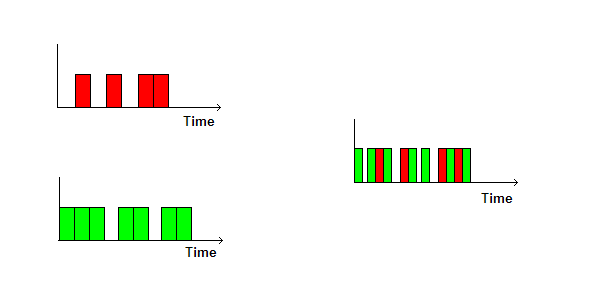
CC0 Creative CommonsMultiplexing a divisione di lunghezza d'onda, WDM oppure wavelength division multiplexing, usato nella fibra ottica per avere tanti segnali luminosi con lunghezze d'onda diverse e non sovrapponibili.
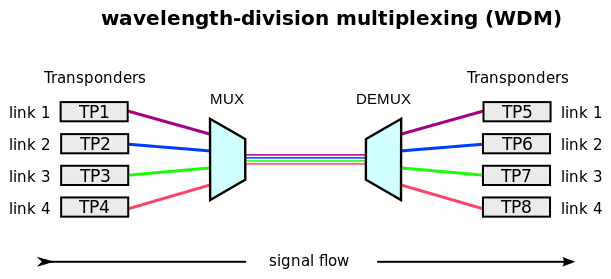
CC0 Creative Commons
Ricapitolando, invece, per Internet, la commutazione di pacchetto:Occupa banda solo se necessario;
Risulta semplice da implementare;
Non necessita di un costo per creare il circuito, in quanto su internet non viene creato;
Risulta più efficiente ed adatto ad un traffico con alternanza picchi-silenzi, detto anche burst
{kind=link}
{kind=link}
{kind=link}
Però come CONTRO:
- Non garantisce alti livelli di prestazioni;
- Soffre notevolmente di congestione, specie in periodi di traffico, e spesso e volentieri butta i pacchetti, sopratutto se i buffer dei router sono pieni;
Su quale architettura si basa Internet?
Internet è organizzata a livelli, o strati, layer ed ad ognuno di essi viene garantito uno o più servizi. Un'architettura di rete può far riferimento al modello TCP/IP oppure al modello OSI/ISO, anche se quest'ultimo è prettamente teorico e TCP/IP potremmo dire che deriva da OSI/ISO anche se è stato implementato prima; in effetti il modello OSI/ISO fu successivo al modello TCP/IP eppure ne descrive il funzionamento aggiungendo alcuni livelli che nel secondo non vengono considerati. Entrambi sono a livelli e due livelli adiacenti possono interagire tra loro attraverso un'interfaccia: i livelli inferiori forniscono i propri servizi ai livelli superiori. L'implementazione dei vari servizi è interna a ciascun livello e quindi una sua modifica non crea problemi a patto di non modificare l'interfaccia. Il fatto di essere a livelli consente di separare i problemi e semplificare il tutto (secondo una strategia detta top-down). Ogni servizio, infine, presenta due tipi di interfacce:
- interfaccia di servizio consente di far comunicare livelli adiacenti;
- interfaccia di livello, detta anche peer to peer, pari a pari, consente la comunicazione con una controparte presente su un'altro host;
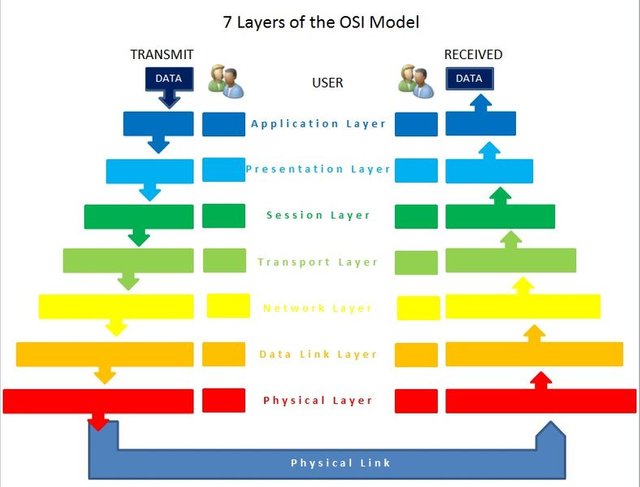
Secondo il modello, che considereremo, di riferimento ISO - International Standard Organization/OSI - Open System Interconnection, Internet è formato da 7 livelli:
- Fisico, gestisce la trasmissione fisica dei bit nel cavo;
- Collegamento, organizza i bit in frame e li consegna attraverso protocolli quali: Ethernet, Wi-Fi, DOCSIS, PPP (Point-to-Point protocol);
- Rete, consente lo spostamento di pacchetti dalla sorgente alla destinazione, detti datagrammi. Comprende il protocollo IP che fornisce un servizio best effort oltre a vari protocolli per instradare il datagramma: ARP, RARP, ICMP, IGMP;
- Trasporto, rende un servizio di trasferimento dati da processo a processo. Sfrutta due protocolli: TCP Transmission Control Protocol e UDP User Datagram Protocol; il primo fornisce un servizio per connessione spezzando il messaggio in segmenti, effettua un controllo della congestione della rete; il secondo invece fornisce un servizio senza garantire affidabilità ma più veloce nella consegna. Vi è anche STP Stream Control Transmission utilizzato per servizi di streaming sia audio sia video. Preferireste un postino che inspira fiducia e vi garantisce che il vostro pacco arriverà a destinazione dopo molto tempo o un postino poco affidabile che però impiega meno tempo?
- Sessione, gestisce e termina una sessione di comunicazione anche se non viene mai implementato;
- Presentazione, cambia il formato e crittografa le informazioni comprimendole, anche questo non viene praticamente implementato;
- Applicazione, consente l'accesso alle risorse di rete ed include protocolli quali: HTTP, SMTP, FTP, DNS; inoltre i livelli 5 e 6 vengono inglobati in questo livello;
CC0 Creative Commons
{kind=link}
Cosa sono le applicazioni in rete?
Il cuore dello sviluppo delle applicazioni di rete è costituito da programmi che vengono eseguiti su computer diversi e che comunicano tra loro tramite la rete. Un esempio comune è il browser eseguito sul nostro computer e il web server di Google a cui accediamo. Una applicazione viene progettata dallo sviluppatore secondo una architettura Client-Server o una Peer-To-Peer.
Nell'architettura Client-Server vi è un host sempre attivo, il Server, che risponde a tutte le richieste di servizio di altri host, i Client. Questi ultimi non comunicano direttamente tra loro ma vi è il Server da intermediario, esso infatti presenta un indirizzo IP fisso e il Client lo può contattare in qualsiasi momento. Alcuni esempi di applicazioni Client-Server sono il Web o la posta elettronica. Per garantire un servizio su vasta scala, si usano i data center dove vengono ospitati tanti Server. I servizi di ricerca (Google, Yahoo ecc.), di commercio (Amazon, eBay ecc.), di posta (Gmail, Libero Mail ecc.) ed i social network come Facebook e Twitter sfruttano uno o più data center, a cui necessita alimentazione e manutenzione.
Nell'architettura Peer-to-Peer, i data center sono in numero minimo o del tutto assenti. Di fatto, si sfrutta la comunicazione diretta tra coppie di host detti tra loro peer, pari. Le principali applicazioni che presentano elevato traffico si basano sul P2P, alcuni esempi: condivisione di file (BitTorrent e molti altri), telefonia su Internet (Skype) e IPTV, ovvero lo streaming. Punto di forza del P2P è la scalabilità, ovvero ogni peer aggiunge capacità di servizio al sistema rispondendo alle richieste di altri peer; ciò li porta ad essere economicamente convenienti.
In realtà vi sarebbe anche una terza architettura che è ibrida, rappresentano la categoria di applicazioni di messaggistica istantanea come WhatsApp o Telegram.
CC0 Creative Commons
Si conclude così l'articolo per oggi, spero sia stato interessante e gradevole alla lettura come sempre. Vi ringrazio per il tempo che dedicate per leggere e vi auguro una buona giornata. Infine vi riporto la bibliografia:
- S. Ihm, V. S. Pai, Towards Understanding Modern Web Traffic, Proc. 2011
ACM Internet Measurement Conference (Berlin); - S. Halabi, Internet Routing Architectures, 2nd Ed., Cisco Press, 2000;
- L. Gauthier, C. Diot, and J. Kurose, End-to-end Transmission Control
Mechanisms for Multiparty Interactive Applications on the Internet, Proc. 1999 IEEE INFOCOM (New York, NY, Apr. 1999); - B. Davie and Y. Rekhter, MPLS: Technology and Applications, Morgan
Kaufmann Series in Networking, 2000; - Y. Chen, S. Jain, V. K. Adhikari, Z. Zhang, Characterizing Roles of Front-End
Servers in End-to-End Performance of Dynamic Content Distribution, Proc. 2011 ACM Internet Measurement Conference (Berlin, Germany, Nov. 2011)
Grazie mille della delucidazione. E la blockchain in tutto questo si può riassumere in un nuovo protocollo che permette un'automatizzazione dell'affidabilità, della tracciabilità e della trasparenza di dati P2P che altrimenti potrebbero facilmente essere manipolabili?
Attenzione: la blockchain è un processo di scambio tra più host di risorse e tutti gli host che partecipano alla blockchain ricevono i dati condivisi (di fatti la piattaforma che usiamo si basa proprio su questo: pubblichiamo 'risorse' e tutti i partecipanti a steemit la ricevono). È essenzialmente una tecnologia non un protocollo, anzi si fonda su architetture quali appunto il P2P e sfrutta anche la crittografia onde evitare che i nostri dati (soprattutto se sensibili) cadano in mani diverse dalle nostre. Sono, quindi, due aspetti separati ma che si legano tra loro perchè uno sfrutta l'altro e certamente come dice Lei consente di automatizzare operazioni che altrimenti richiederebbero molto tempo all'utente. Inoltre l'affidabilità viene garantita grazie alla rete sottostante, di fatti i servizi forniti nei livelli inferiori del modello OSI/ISO (di cui andrò a spiegarne il funzionamento in un articolo futuro) garantiscono l'affidabilità. La tracciabilità e la trasparenza son anch'esse garantite ma perchè oggigiorno i dispositivi vengono muniti di 'intelligenza' tale da riuscire a tracciare una qualsiasi persona per i suoi gusti, per le sue attitudini e per molto altro ancora (basti pensare alle ultime tecnologie sviluppate come il riconoscimento facciale, ma si può anche semplicemente prendere ad esempio la carta di credito o le attività che si svolgono sulla rete).
Quante informazioni!! Articolo molto interessante, spesso ci si mette al computer e non ci si rende conto di tutto quello che c'è dietro e che ne permette il funzionamento!
È proprio questo il motivo percui porto questo contenuto, che a mio avviso reputo molto interessante, perchè mostra l'altra faccia della medaglia di Internet (nel bene e nel male).
E' vero e concordo anche sul fatto che sia molto interessante ;-)