Prédire les survivants du Titanic à l'aide de l'intelligence artificielle

Avec nos connaissances actuelles, nous pouvons, à l’aide de l’intelligence artificielle, prévoir des conséquences résultantes de certaines données que nous avions à l’origine. Dans cet article, nous allons essayer de déterminer les personnes survivantes lors de la catastrophe du Titanic. Pour réaliser cette étude, nous allons nous servir des données mises à disposition par Kaggle. Tout au long de cet article, nous utiliserons Google Colab. Nous vous invitons à l’utiliser afin de suivre avec nous la réalisation de ce projet. Bien entendu, vous pouvez, si vous le souhaitez, réaliser ce projet sur votre machine personnelle.
Présentation du problème
Nous connaissons tous le terrible accident qu’il y a eu avec le fameux bateau nommé le Titanic. Nous avons récupéré diverses informations sur les personnes ayant pris un ticket sur ce bateau et si elles ont survécu ou non à l’accident. Cependant, nous avons en notre possession une liste d’information de personnes dont nous ne savons pas si elles ont survécu. Notre objectif est donc de réaliser un système intelligent qui pourra nous déterminer si ces personnes ont survécu ou non à ce désastre.
Téléchargement des données
La première étape consiste à télécharger les données. Pour ce faire, nous allons nous rendre sur Kaggle. Il vous faudra vous créer un compte si ce n’est pas déjà le cas pour pouvoir télécharger les données nécessaires.
Une fois télécharger, vous devriez avoir deux fichiers qui vont nous intéresser, à savoir le fichier test.csv et le fichier train.csv. Comme vous pouvez vous en doutez, nous avons ici un fichier qui correspond à notre base d’entraînement et un autre fichier qui correspond à notre base de validation.
Comprendre les données
Avant de foncer dans une recherche de solution, nous allons visualiser nos données. Pour cela, nous allons, à l’aide de la librairie pandas, visualiser quelques éléments de notre base d’entraînement.
import pandas as pd
# Import all the data.
test_data = pd.read_csv('test.csv')
train_data = pd.read_csv('train.csv')
# Print some example of our data.
train_data.head()
Affichage de quelques données.

Comme nous pouvons le constater, sur la base d’entraînement, nous avons au total 12 attributs. Nous allons, dans un premier temps, comprendre la signification de chacune de ces variables et voir comment elles sont représentées.
PassengerId
Le passengerId représente un identifiant unique pour nos données. Ainsi, cet identifiant n’influencera pas le résultat de notre étude. Nous pouvons donc exclure cette variable de notre étude.
Survived
Survived correspond à une valeur booléenne représentant la valeur 0 si la personne n’a pas survécu et la valeur 1 si elle a survécu. Durant notre étude, c’est cette valeur que nous allons chercher à prédire. Pour ce faire, nous allons chercher des relations possibles en fonction des différents attributs que nous avons à notre disposition.
Pclass
Pclass représente la classe du ticket. Cette variable est représentée par trois classes distinctes : la classe 1, 2 et 3. Sous python, nous pouvons visualiser la quantité des différentes catégories en utilisant :
train_data["Pclass"].value_counts()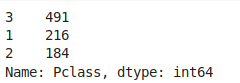
Nombre de personnes pour chaque classe de tickets.
Comme nous pouvons le constater, nous avons davantage de personnes appartenant à la catégorie 3. On pourrait se poser la question de savoir si la classe du ticket influe sur le fait de survivre ou non. Pour cela, nous allons visualiser cela en affichant le pourcentage de survivant en fonction de leur classe de ticket. Pour ce faire, nous allons utiliser la commande suivante :
train_data[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False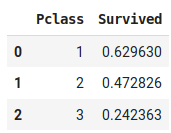
Pourcentage de survivant en fonction de la classe du ticket.
Comme vous pouvez le remarquer, en fonction de la classe du ticket, nous avons plus ou moins de chances de survivre. Ainsi, nous pouvons supposer que la classe du ticket de la personne a une importance.
Name
Pour chacune des personnes présentes, nous avons accès à son nom. Il peut être intéressant de récupérer des informations sur le nom. En effet, nous avons remarqué que pour certaines valeurs, nous avons la catégorie sociale de la personne. Cependant, dans cet article, pour des raisons de simplicité, nous ne nous intéresserons pas au nom de la personne.
Sex
Nous avons aussi à notre disposition le sexe de la personne. Ainsi, on peu savoir si la personne est un homme ou une femme. Une des premières suppositions que nous pouvons émettre est qu’une personne de type masculin aurait une chance de survie plus importante. Cependant, en analysant nos données, nous nous rendons compte que les femmes ont davantage survécu durant ce drame. Ainsi, notre supposition initiale se révèle erronée.
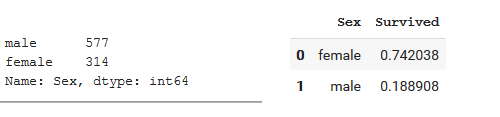
Étude sur le sexe des survivants.
Ainsi, lorsque nous arrivons sur un jeu de données, nous pouvons avoir des a priori sur nos données. Cependant, il nous faut les confirmer avant de pouvoir les affirmer.
Age
Afin de visualiser l’âge des personnes présentes, nous pouvons nous aider en utilisant un histogramme. Pour ce faire, nous allons utiliser la librairie matplotlib de python. Attention, il nous faudra enlever les valeurs Nan présentes dans notre ensemble de données. En effet, pour 177 personnes, l’âge n’est pas défini.
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.hist(train_data["Age"], 50, density=True, facecolor='b', alpha=0.75)
plt.show()
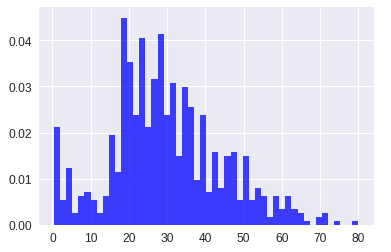
Répartition de l'âge des personnes présentent sur le Titanic.
Une autre méthode de visualisation consiste à dessiner une aire nous indiquant les personnes qui ont survécu et les personnes qui n’ont pas survécu en fonction de leur âge. Pour ce faire, nous allons utiliser la librairie python seaborn.
import seaborn as sns
import pandas as pd
g = sns.kdeplot(train_data["Age"][(train_data["Survived"] == 0) & (train_data["Age"].notnull())], color="Red", shade = True)
g = sns.kdeplot(train_data["Age"][(train_data["Survived"] == 1) & (train_data["Age"].notnull())], ax =g, color="Blue", shade= True)
g.set_xlabel("Age")
g.set_ylabel("Frequency")
g = g.legend(["Not Survived","Survived"])
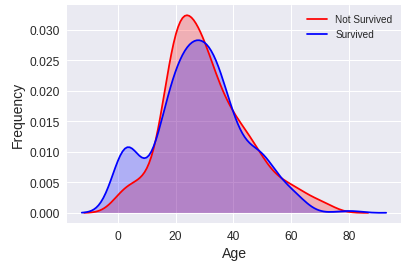
Fréquence de personnes ayant survécu ou non par rapport à leur âge.
Avec la dernière figure, nous pouvons constater qu'une grande partie des personnes ayant un âge compris entre 0 et environ 16 ans ont survécu. Nous pouvons apercevoir qu’une plus grande partie des personnes ayant 20 ans n'ont pas survécu. De plus, nous constatons que les personnes qui ont plus de 60 ans n'ont pas survécu aussi. Ainsi, nous pourrions créer 4 groupes de personnes. Les enfants qui seraient les personnes âgées de 0 à 16 ans, les jeunes qui seraient âgés de 16 à 30 ans, les moins jeunes de 30 à 60 et les personnes âgées qui seraient les personnes de plus de 60 ans.
Enfin, nous avons un problème vis-à-vis des données manquantes. En effet, cela peut-être problématique lors de la phase d’apprentissage, car notre système ne sera pas comment interpréter une donnée manquante. L’une des solutions serait d’utiliser la médiane ou la moyenne afin d’obtenir une valeur. Cependant, cela peut insérer un biais dans nos données. Une autre possibilité serait d’utiliser un système intelligent afin de réaliser une prédiction de cette valeur manquante. Pour ce faire, nous pourrions nous baser sur les informations à notre disposition afin de pouvoir déterminer l’âge de la personne.
SibSp
Cet attribut nous indique le nombre de frères et sœurs présent sur le navire, ainsi que le nombre de conjoints. Lorsque nous analysons cette donnée, nous pouvons apercevoir qu’une grande majorité de personne présente sur le navire ne possède pas de frères, de sœurs ou de conjoint.

Étude sur le nombre de frères, de sœurs et de conjoints.
Encore une fois, nous allons chercher à savoir si cette variable a un effet sur le fait de survivre ou non.
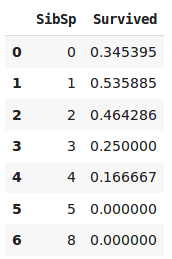
Étude sur le nombre de frères, de sœurs et de conjoints des survivants.
À l'aide de la figure précédente, nous pouvons nous rendre compte que les personnes ayant un ou deux frères et/ou sœurs et/ou conjoints ont plus de chance de survivre. En revanche, au-delà, ils ont de moins en moins de chance de survivre.
Parch
La variable Parch correspond au nombre de parents/enfants présent sur le navire lors du drame.

Étude sur le nombre de parents/enfants.
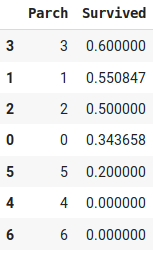
Étude sur le nombre de parents/enfants des survivants.
À l'aide du dernier graphique, nous pouvons constater que les passagers ayant 1 à 3 parents/enfants ont plus de chances de survivre que les autres. Cependant, il faut faire attention au nombre de personnes que nous prenons en compte. En effet, dans le cas où la variable Parch est égale à 3, nous pouvons constater que nous avons seulement 5 personnes. Ainsi, 3 personnes suffisent pour avoir une probabilité élevée. Cependant, nous ne pouvons pas dire avec certitude qu'avoir une valeur de 3 pour cette variable nous donne une probabilité plus haute de survivre.
Ticket
Nous avons accès à l’information sur le ticket des personnes. Ainsi, pour chaque personne, nous avons une chaîne de caractères composée soit que de chiffres, soit de lettres puis de chiffres. On peut constater qu’il y a seulement 681 unique ticket sur les 891 données que nous avons dans notre base d’entraînement. Cependant, un ticket devrait être unique pour tous les passagers de notre bateau. Ainsi, ce ne serait pas intéressant de garder cette information. Cependant, le fait que certains éléments soient composés de préfixe est intéressant. En effet, nous pouvons penser qu’en fonction de ce préfixe, nous pourrons déterminer une zone regroupant les mêmes cabines. Ainsi, lors du drame, les conséquences liées à certaines cabines dans une zone seront répercutées sur les autres cabines appartenant à la même zone. Ainsi, dans notre étude, nous pourrions récupérer cette information.
Fare
L’attribut Fare représente le prix du ticket. La première chose que nous pouvons constater est que nous avons dans notre base d’entraînement une valeur pour chaque élément. Cependant, nous pouvons constater qu’il nous manque une donnée pour notre base de test. Dans un premier temps, nous allons chercher à analyser les valeurs présentes dans notre base d’entraînement.
train_data["Fare"].describe()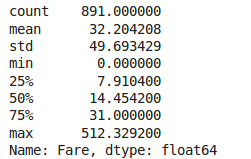
Analyse du prix des tickets.
La première chose que nous pouvons remarquer est que le prix d’un ticket est très concentré. En effet, on peut voir que la médiane est d’environ 14,5. Puis, la valeur d’un ticket devient de plus en plus conséquente. Cependant, étant donné que nous avons des valeurs concentrées, une des approches que nous pouvons faire afin de prédire la valeur manquante serait de prendre la médiane. Bien entendu, nous aurions pu prendre un autre indicateur comme la moyenne. Dans notre cas, nous ne prenons pas la moyenne, car si nous regardons la valeur de l'écart-type, nous pouvons constater qu'elle est assez conséquente. Cela signifie donc que nos valeurs sont très éparpillées et qu'il est possible que nous ayons des valeurs aberrantes et peut-être fausses. Ainsi, nous préférons prendre la médiane.
Cabin
L’attribut Cabin représente les cabines où sont les passagers lors de leurs voyages. Cet attribut va nous poser problème. En effet, nous avons de nombreuses données manquantes. De plus, les données manquantes sont à la fois dans notre base d’entraînement et notre base de test. Elles sont présentes dans environ ¼ de nos données de test et presque 2/9 de nos données d’entraînement. Ainsi, dans notre étude, nous allons ignorer ces données. Cependant, cette donnée semble intéressante pour cette étude. En effet, en fonction de l’emplacement de la cabine du passager, la personne aurait pu mettre davantage de temps pour être évacué et ces chances de survie auraient pu être impactées.
Embarked
L'attribut "Embarked" correspond au port d'embarcation des personnes. Pour le cas de l’attribut “Embarked”, nous pouvons remarquer que nous avons deux valeurs non définies dans notre base d’entraînement. Cependant, dans notre base de test, nous pouvons apercevoir que nous avons l’ensemble de nos éléments. Afin de ne pas nous compliquer la tâche, nous pouvons simplement supprimer les deux données où nous avons l’attribut manquant.
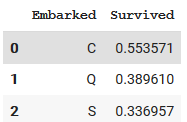
Étude sur le port d'embarquement des survivants.
En étudiant l'influence de cet attribut, nous pouvons constater que les personnes embarquant au port de Cherbourg ont plus de chance de survivre que les personnes embarquant à Queenstown ou à Southampton.
Rétrospection de notre analyse
Lors de cette analyse, assez fastidieuse, je vous l'accorde, nous avons cherché à comprendre chacune de nos données. De plus, nous avons aussi cherché à trouvé un lien entre les attributs et l'attribut recherché, ici le fait de survivre ou non. Nous nous sommes aussi concentrés sur le nombre d'attributs présents. En effet, afin de pouvoir traiter nos données, nous avons besoin d'information. Or, si cette dernière est manquante ou incomplète, nous ne pouvons pas nous appuyer dessus. Ainsi, il nous faut soit retirer de notre étude certains attributs ou associer une valeur à nos données manquantes.
Nous pouvons critiquer notre méthode, car lors de notre étude, nous recherchons une correspondance de manière visuelle sans trop nous appuyer sur des outils mathématiques nous permettant de quantifier cette correspondance. De plus, lors de notre aperçu des variables, nous avons cherché à mettre en relation uniquement une variable et le résultat. Or, il se peut que certaines variables aient du sens que lorsque nous les associons avec d'autres. Par exemple, l'âge et le nombre de frères et sœurs ont peut-être de meilleur résultat ensemble que pris séparément.
Bien entendu, dans un cas réel, il nous faudrait prendre tous cela en compte. Faire une étude des différentes variables que nous avons à notre disposition et les mettre en relation. Dans cet article, nous voulons simplement vous montrer la démarche à entreprendre. Dans de futurs articles, nous nous attarderons davantage sur cette partie délaissée ici.
Transformation des données
Après notre analyse, nous avons vu que certaines variables étaient intéressantes. Cependant, elles n'étaient pas forcément exploitables directement. Il va donc nous falloir appliquer un traitement afin de pouvoir les exploiter par la suite.
Modification des tickets
Dans notre étude, nous avons fait le choix de conserver la variable liée au ticket. Afin de pouvoir l'exploiter, nous avons décidé d'enlever les caractères posant problème. En effet, en étudiant les différents tickets possibles, nous nous rendons compte que certains tickets ont parfois les mêmes valeurs. Cela s'explique par le fait que le nombre n'est parfois pas conservé et que nous avons un préfixe indiquant potentiellement un emplacement sur le navire. Ainsi, nous avons voulu exploiter cela. Pour ce faire, nous réalisons une transformation en exécutant le code qui suit :
Ticket = []
for i in list(train_data["Ticket"]):
if not i.isdigit() :
Ticket.append(i.replace(".","").replace("/","").strip().split(' ')[0])
else:
Ticket.append("X")
train_data["Ticket"] = Ticket
train_data["Ticket"].value_counts()
Piste d'améliorations
Il est possible de traiter d'autres variables comme l'âge qui peut être un facteur intéressant dans notre étude. Pour cette dernière, plusieurs choix s'offrent à nous. La première consiste à normaliser la variable âge pour qu'elle soit comprise entre 0 et 1. La seconde consiste à créer des catégories d'âges en fonction de la proportion survivant ou non. Il nous suffira ensuite d'encoder la catégorie sous le format One-hot.
Bien entendu, d'autres variables peuvent être utilisé même si certaines ont des données manquantes. Sur ces dernières, il faudrait en définir une de base par calcul de la moyenne ou de la médiane... ou par prédiction. En effet, rien ne nous empêche de réaliser un système intermédiaire permettant de déterminer la valeur manquante.
Préparation de notre production
Avec la librairie python sklearn, nous avons la possibilité de créer des pipelines. Cela nous permet d'appliquer un traitement sur nos données en le spécifiant au préalable. Cette méthode est très avantageuse, car si nous avons beaucoup d'ensemble de données que nous souhaitons tester, nous pouvons réaliser le traitement en appelant une seule fonction. Or, si nous réalisons pour chacun des ensembles un traitement séparer, cela peut être très fastidieux. De plus, nous avons des risques d'erreur lors de la réalisation du traitement à la main. Bien évidemment, la création de ce traitement est parfois complexe et peut prendre un peu de temps. Cependant, de mon point vue, cela est largement rentabiliser sur le long terme.
Ainsi, dans cette étude, nous allons réaliser une pipeline pour ce jeu de données. Nous allons créer une classe python permettant de sélectionner les données, sans appliquer de traitement sur celle-ci.
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names]Avec cette classe, nous allons pouvoir sélectionner les variables que nous souhaitons conserver sans appliquer de traitement sur elles.
from sklearn.pipeline import Pipeline
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
num_pipeline = Pipeline([
("select_numeric", DataFrameSelector(["SibSp", "Parch", "Fare"])),
("imputer", SimpleImputer(strategy="median")),
])Nous allons créer une autre classe de sélection, qui cette fois-ci va appliquer aux valeurs manquantes la valeur la plus fréquente.
class MostFrequentImputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X],
index=X.columns)
return self
def transform(self, X, y=None):
return X.fillna(self.most_frequent_)Et nous allons appliquer cela sur les éléments qui nous intéresse :
cat_pipeline = Pipeline([
("select_cat", DataFrameSelector(["Pclass", "Sex", "Embarked", "Ticket"])),
("imputer", MostFrequentImputer()),
("cat_encoder", OneHotEncoder(sparse=False)),
])
Enfin, nous allons rassembler ces deux pipelines dans une seule. Ainsi, lorsque nous appellerons cette dernière, elle appliquera les deux traitements.
from sklearn.pipeline import FeatureUnion
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])Entraînement de notre modèle
Avant de pouvoir entraîner notre modèle, il nous faut récupérer nos données, mais aussi sélectionner un modèle pertinent pour notre étude. Pour récupérer nos données d'entraînement, nous faisons :
X_train = preprocess_pipeline.fit_transform(train_data)
y_train = train_data["Survived"]Pour ce cas d'étude, plusieurs types de réseaux sont possibles comme les Support Vector Classifier ou les Random Forest Classifier. Ici, nous allons essayer ces deux modèles et les comparer.
Support Vector Classifier
Nous allons dans un premier temps, à l'aide de la librairie sklearn de python, initialiser notre classifier.
from sklearn.svm import SVC
svm_clf = SVC(gamma="auto")
svm_clf.fit(X_train, y_train)Puis, nous allons réaliser une validation croisée :
from sklearn.model_selection import cross_val_score
svm_scores = cross_val_score(svm_clf, X_train, y_train, cv=10)
svm_scores.mean()Nous obtenons un score d'environ 0.78, ce qui est plutôt bon pour une première approche plutôt basique.
Random Forest Classifier
Nous allons faire la même chose que pour le précédent classifier. Nous allons créer notre modèle et réaliser une validation croisée.
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_scores = cross_val_score(forest_clf, X_train, y_train, cv=10)
forest_scores.mean()Ici, nous obtenons un score d'environ 0.80, un meilleur score que précédemment.
Comparaison des deux modèles
Maintenant, ce qui peut-être intéressant est de comparer nos deux réseaux. En effet, d'après les résultats précédents, nous pouvons dire que le classificateur par Random Forest est meilleur. Cependant, nous allons chercher à visualiser cet écart. Pour ce faire, nous allons nous intéresser à la précision.
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
plt.figure(figsize=(8, 4))
plt.plot([1]*10, svm_scores, ".")
plt.plot([2]*10, forest_scores, ".")
plt.boxplot([svm_scores, forest_scores], labels=("SVM","Random Forest"))
plt.ylabel("Accuracy", fontsize=14)
plt.show()
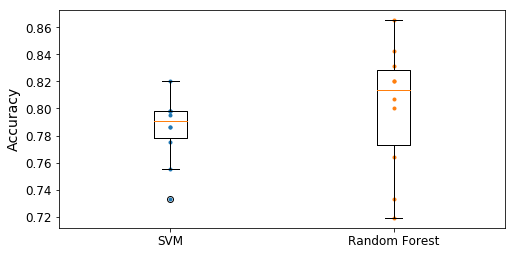
Boîtes à moustache des deux classificateurs.
À l'aide de ces boîtes à moustache, nous pouvons visualiser la précision de nos deux classificateurs. En effet, nous pouvons constater que la précision de notre SVM est très concentrée, alors que celle de notre Random Forest est très étalée. Ainsi, nous avons un modèle plus stable qu'un autre. Il faut en prendre compte. En effet, en fonction de notre cas d'application, cela peut avoir de grandes répercutions.
Rétrospective sur nos classificateurs
Lors de la réalisation de nos modèles, nous ne nous sommes pas attardés sur l'étude des hyper-paramètres. En effet, en modifiant ces paramètres, nous pouvons avoir des résultats très différents. Ainsi, pour avoir un modèle très performant sur nos données, il nous faudrait sélectionner ces hyper-paramètres en testant les différentes possibilités. De plus, dans notre analyse, nous nous sommes limités à deux modèles. Cependant, rien ne nous empêche d'en tester davantage.
Conclusion
Dans cet article, nous avons tenté de prédire les survivant du Titanic en se basant sur un jeu de données. Lors de cette étude, nous avons étudié les différentes variables présentes et transformé les variables qui nous intéresser afin de pouvoir les exploiter. Puis, nous avons réalisé deux systèmes de prédictions en effectuant une validation croisée.
À travers cette étude, nous avons vu les bases de la création d'un système implémentant un système de prédictions. Bien entendu, nous pouvons critiquer notre modèle étant donné que nous pouvions grandement l'améliorer en prenant en considération d'autres variables comme l'âge dans notre système. De plus, d'autres modifications auraient pu être apportées si nous avions analysé davantage les différentes relations entre les variables. Enfin, concernant le système choisi, nous aurions pu en utiliser d'autres, voir améliorer ce que nous avions utiliser en ajustant les hyper-paramètres.
J'espère que cet article, plutôt long, vous aura plus. N'hésitez pas à poser des questions dans les commentaires. Il se peut que certains points ne soient pas clair pour vous. Merci et à bientôt dans un prochain article.
Bibliographie
https://www.kaggle.com/c/titanic/data
https://github.com/ageron/handson-ml/blob/master/03_classification.ipynb
https://www.kaggle.com/ldfreeman3/a-data-science-framework-to-achieve-99-accuracy/log
https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python
https://www.kaggle.com/startupsci/titanic-data-science-solutions
https://www.kaggle.com/yassineghouzam/titanic-top-4-with-ensemble-modeling
Lien original : https://www.technologieintelligente.fr/intelligence-artificielle/cas-dapplication/predire-les-survivants-du-titanic-a-l-aide-de-lintelligence-artificielle/
Félicitations ! Votre post a été sélectionné de part sa qualité et upvoté par le trail de curation de @aidefr !
La catégorie du jour était : #technologie
Si vous voulez aider le projet, vous pouvez rejoindre le trail de curation ici!
Bonne continuation !
Rendez-vous sur le nouveau site web de FrancoPartages ! https://francopartages.xyz
Article passionnant sur un domaine tout aussi passionnant. Pourtant c'était pas gagné car suis vraiment pas un fan de Titanic Hahahaha.
Merci beaucoup :)
C'est vrai que le sujet du Titanic n'est pas forcément le meilleur sujet, mais c'est un cas d'étude assez intéressant qui prend en compte différents aspects de l'analyse de données.
Ce post a été supporté par notre initiative de curation francophone @fr-stars.
Rendez-vous sur notre serveur Discord pour plus d'informations
This post has been voted on by the SteemSTEM curation team and voting trail. It is elligible for support from @curie and @utopian-io.
If you appreciate the work we are doing, then consider supporting our witness stem.witness. Additional witness support to the curie witness and utopian-io witness would be appreciated as well.
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!
Please consider setting @steemstem as a beneficiary to your post to get a stronger support.
Please consider using the steemstem.io app to get a stronger support.
Congratulations @rerere! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPVote for @Steemitboard as a witness to get one more award and increased upvotes!
Hi @rerere!
Your post was upvoted by Utopian.io in cooperation with @steemstem - supporting knowledge, innovation and technological advancement on the Steem Blockchain.
Contribute to Open Source with utopian.io
Learn how to contribute on our website and join the new open source economy.
Want to chat? Join the Utopian Community on Discord https://discord.gg/h52nFrV