Thinking about Big Data
Thinking about Big Data
big data, data mining, sql
Big Data is Big News, a Big Deal, and Big Business, but what is it, really? What does Big Data even mean? To those in the thick of it, Big Data is obvious and I’m stupid for even asking the question. But those in the thick of Big Data find most people stupid, don’t you? So just for a moment I’ll speak to those readers who are, like me, not in the thick of Big Data. What does it mean? That’s what I am going to explore this week in what I am guessing will be three long columns.
My PBS series Triumph of the Nerds was the story of the personal computer and its rise to prominence from 1975-95. Nerds 2.01: A Brief History of the Internet was the story of the Internet and its rise to prominence from 1966-98. But each show was really about the effect of Moore’s Law on technology and society. Personal computers became possible only when the cost of microprocessors dropped to where they could be purchased by individuals. It could not have happened before reaching this tipping point where the market was ready for explosive growth.
The commercial Internet in turn became possible only when the price of servers dropped another two orders of magnitude by the mid-1990s, making dial-up Internet economically feasible and creating another tipping point. Thinking in similar terms, Big Data is what happened when the cost of computing dropped yet another two orders of magnitude by 2005 making possible the most recent tipping point. We pretend that this happened earlier, in 1998, but it didn’t (that’s part of the story). 2005 marked the emergence of mobile computing, cloud computing, and the era of Big Data. And just as we did in my two documentary series, we as a people stand again on the cusp of a new era with virtually no understanding of how we got here or what it really means.
Personal computing changed America, the Internet changed the world, but Big Data is about to transform the world. Big Data will drive our technological development for the next hundred years.
Wherever you are in the world, computers are watching you and recording data about your activities, primarily noting what you watch, read, look at, or buy. If you hit the street in almost any city, surveillance video can be added to that: where are you, what are you doing, who or what is nearby? Your communications are monitored to some extent and occasionally even recorded. Anything you do on the Internet — from comments to tweets to simple browsing — never goes away. Some of this has to do with national security but most of this technology is simply to get you and me to buy more stuff — to be more efficient consumers. The technology that makes all this gathering and analysis possible was mainly invented in Silicon Valley by many technology startup companies.
How did we get here and where are we going? You see technology is about to careen off on new and amazing paths but this time, rather than inventing the future and making it all happen the geeks will be more or less along for the ride: new advances like self-driving cars, universal language translation, and even computers designing other computers are coming not from the minds of men and women but from the machines themselves. And we can blame it all on Big Data.
Big Data is the accumulation and analysis of information to extract meaning.
Data is information about the state of something — the who, what, why, where, when, and how of a spy’s location, the spread of disease, or the changing popularity of a boy band. Data can be gathered, stored and analyzed in order to understand what is really happening, whether it is social media driving the Arab Spring, DNA sequencing helping to prevent disease. or who is winning an election.
Though data is all around us in the past we didn’t use it much, primarily because of the high cost of storage and analysis. As hunter-gatherers for the first 190,000 years of homo sapien life we didn’t collect data at all, having no place to keep it or even methods for recording it. Writing came about 8000 years ago primarily as a method of storing data as our culture organized, wanted to write down our stories, and came to need lists concerning population, taxes, and mortality.
Lists tend to be binary — you are on or off, dead or alive, tax-paying or tax-avoiding. Lists are about counting, not calculating. Lists can contain meaning, but not that much. What drove us from counting to calculating was a need to understand some higher power.

Thousands of years ago the societal cost of recording and analyzing data was so high that only religion could justify it. In an attempt to explain a mystical world our ancestors began to look to the heavens, noticing the movement of stars and planets and — for the first time — writing down that information.
Religion, which had already led to writing, then led to astronomy and astronomy led to mathematics all in search of mystic meaning in celestial movement. Calendars weren’t made up, for example: they were derived from data.
Data has been used through history for tax and census rolls and general accounting like the Domesday Book of 1086 — essentially a master tax record of Britain. There’s the operant term count. Most of the data gathered through history was by counting. If there was a lot of data to be considered (more than a few observations required in a scientific experiment) it nearly always had to do with money or some other manifestation of power (how many soldiers, how many taxpayers, how many male babies under the age of two in Bethlehem?). Every time you count, the result is a number and numbers are easy to store by writing them down.

Once we started accumulating knowledge and writing it down it was in our nature to seek ways to hide these data from others. This led to codes and cyphers and to statistical techniques for breaking them. A 9th century scientist named Abu Yusuf al-Kindi, wrote A Manuscript on Deciphering Cryptographic Messages, marking the beginning of statistics — the finding of meaning in data — and of cryptanalysis or code-breaking.
In his book al-Kindi promoted a technique now called frequency analysis to help break codes where the key was unknown. Most codes were substitution cyphers where every letter was substituted with another. If you knew which letter was which it was easy to decode. al-Kindi’s idea was that if you knew how frequently each letter was used in typical communication that frequency would be transferred unchanged to the coded message.

In English the most frequent letters are e, t, a, and o in that order. So given a large enough message to decode, whatever letter appears most frequently ought to be an e and so on. If you find a q it nearly always is followed by u, etc. That is unless the target language isn’t English at all.
What’s key in any frequency substitution problem is knowing the relative frequency and that means counting the letters in thousands of common documents, whatever the language — data gathering and analysis circa 900 AD.

But it was another 800 years after al-Kindi before collected data was shown to be of much public use. In London the Bills of Mortality were published weekly starting in 1603 to give a day-by-day accounting of all recorded deaths in London (Bring out your dead!). These weekly reports were later published in an annual volume and that’s where it gets interesting. Though the point of the Bills was simply to create a public record, meaning was eventually found by analyzing those pages after the Plague of 1664-65. Experts were able to plot that plague as it spread across London from infection points mapped on the city’s primitive water and sewer systems. It became clear from those data both the sources of the infection (mosquitoes, rats) and how to stay away from them (be rich, not poor). And so the study of public health was born.
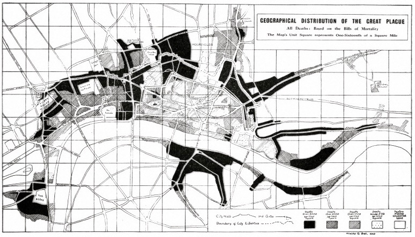
What made Bills of Mortality so useful was not just the data of who died — the sheer numbers — but the metadata (data about the data) saying where the victims lived, where they died, their age, and type of work. The story of the Plague of 1664 could be read by mapping the metadata.
While Bills of Mortality was reputed to be a complete account of the plague, it’s doubtful that was the case. Many deaths were probably missing or attributed to the wrong causes. But one lesson of statistics was that didn’t matter if there was enough data for trends to be clear. In fact as the field of statistics grew in 18th century France it became clear that nearly as much could be learned from a random sample of data as from gathering all the information. We see this today when political pollsters guess elections based on small samples of random voters. The occasional failure of these pollsters to correctly predict election outcomes shows, too, that sampling is far from perfect.
Sampling and polling generates results that we “believe” to be true, but a 100 percent sample like a census or an election generates results we can “know.”
Data processing. Storing data isn’t the same as processing it. Libraries do a pretty good job of storing data but it isn’t very accessible. You still have to find the book, open it, read it and even then the level of detail we can retain is limited by our memories.
American statistician Herman Hollerith in the late 19th century envisioned a system that would automatically gather data and record it as holes punched in paper cards — cards that could then be mechanically sorted to obtain meaning from the data, a process that Hollerith called tabulating. Hollerith received a patent on the technology and his Washington, DC-based Tabulating Machine Company went on to become today’s International Business Machines (IBM).

For decades the primary machine function at IBM was sorting. Imagine those cards were each customer accounts at the electric company. It would be easy to use a machine to sort them in alphabetical order by last name, to sort them by billing date, to sort them by the amount of money owed, to sort them by those past-due and those not, etc. Early data processing meant sorting and punched cards were good for that. Of course people are fairly good at that, too. The reason for using a machine was primarily to save time so all the bills could go out before the end of the month.
The first databases, then, were stacks of those punched cards. If you were the electric company it was easy, too, to decide what should be on the card. Name and address, electricity usage in the current billing period, the date on which the bill is to be sent out, and your current payment status: are you paying your bills?
But what if you wanted to add a new product or service? That would require adding a new data field to every card including those that predated the new product or service. Such changes are the things that confounded mechanical card sorters. So in the spirit of flexibility a new kind of database was born in the 1950s that changed the world of business and travel.
Transaction processing. American Airlines’ SABRE reservation system was the world’s first real time automated system. Not just the first reservation system but the first-ever computer system to interact with operators in real time where business was conducted actually in the machine — a prelude to Big Data. This was back when we still tracked incoming Russian bombers by hand.
Up until SABRE, data processing had been always reactive. Accounting systems looked back at the quarter or month before and figured out how to represent what had already happened, taking as much time as needed to do so. But SABRE actually sold airline seats for future flights against an inventory of seats that existed solely in the computer.
Think of SABRE as a shoebox containing all the tickets for all the seats on AA flight 99. Selling tickets from the shoebox would prevent selling the same seat twice, but what if you wanted to sell the seats at the same time through agents in offices all over the country? That required a computer system and terminals, neither of which yet existed. It took American Airlines founder C.R. Smith sitting on a flight next to IBM’s T.J. Watson Jr. to get that ball rolling.

One key point about the SABRE story is that IBM didn’t have a computer the system could run on, it was so demanding. So American became the launch customer for the biggest computers made to that time. Rather than being programmed for the task, those computers in the world’s first corporate data center in Tulsa, Oklahoma (it’s still there), were hard-wired for selling airline seats and nothing else. Software came later.
American Airlines and SABRE got IBM into the mainframe business and those first systems were designed as much by American as IBM.
SABRE set the trend for data-driven computing applications from the 1950s until the 1980s. Bank tellers eventually got computer terminals, for example, but just like airline reservation agents their terminals only understood one thing — banking — and your status at the bank was typically represented on a single 80-column punched card.
Moore’s Law. As computers were applied to processing data their speed made it possible to delve deeper into those data, discovering more meaning. The high cost of computing at first limited its use to high-value applications like selling airline seats. But the advent of solid state computers in the 1960s began a steady increase in computing power and decrease in computing cost that continues to this day — Moore’s Law. So what cost American Airlines $10 to calculate in 1955 was down to a dime by 1965, to a tenth of a penny by 1975, and to one billionth of a cent today.

The processing power of the entire SABRE system in 1955 was less than your mobile phone today.
This effect of Moore’s Law and — most importantly — the ability to reliably predict where computing cost and capability would be a decade or more in advance, made it possible to apply computing power to cheaper and cheaper activities. This is what turned data processing into Big Data.
But for that to happen we had to get away from needing to build a new computer every time we wanted a new database. Computer hardware had to be replaced with computer software. And that software had to be more open to modification as the data needs of government and industry changed. The solution, called a relational database management system, was conceived by IBM but introduced to the world by a Silicon Valley startup company called Oracle Systems run by Larry Ellison.
Ellison started Oracle in 1977 with $1200. He is now (depending on the day you read this) the third richest man in the world and archetype for the movie character Iron Man.
Before Oracle, data was in tables — rows and columns — held in computer memory if there was enough or read to and from magnetic tape if memory was lacking as it usually was in those days of the 1970s. Such flat file databases were fast but the connections that could be made within the data often couldn’t be changed. If a record needed to be deleted or a variable changed it required changing everything, generating an entirely new database which was then written to tape.
With flat file databases change was bad and the discovery of meaning was elusive.
IBM’s Ted Codd, an expatriate mathematician from England working in San Jose, California, began to see beyond the flat file database around 1970. In 1973 he wrote a paper describing a new relational database model where data could be added and removed and the key relationships within the data could be redefined on the fly. Where before Codd’s model a payroll system was a payroll system and an inventory system was an inventory system, the relational approach separated the data from the application that crunched away on it. Codd saw a common database that had both payroll and inventory attributes and could be modified as needed. And for the first time there was a query language — a formal way to ask questions of the data and flexible ways to manipulate that data to produce answers.
This relational model was a huge step forward in database design, but IBM was making plenty of money with its old technology so they didn’t immediately turn the new technology into a product, leaving that opportunity to Ellison and Oracle.

Oracle implemented nearly all of Codd’s ideas then took the further step of making the software run on many types of computers and operating systems, further reducing the purchase barrier. Other relational database vendors followed including IBM itself and Microsoft, but Oracle remains the biggest player today. And what they enabled was not just more flexible business applications, but whole new classes of applications including human resources, customer relationship management, and — most especially — something called business intelligence. Business intelligence is looking inside what you know to figure out what you know that’s useful. Business intelligence is one of the key applications of Big Data.
The Internet and the World Wide Web. Computers that ran relational databases like Oracle were, to this point, mainframes and minicomputers — so called Big Iron — living on corporate data networks and never touched by consumers. That changed with the advent of the commercial Internet in 1987 and then the World Wide Web beginning in 1991. Though the typical Internet access point in those early years was a personal computer, that was a client. The server, where Internet data actually lived, was typically a much bigger computer easily capable of running Oracle or a similar relational database. They all relied on the same Structured Query Language (SQL) to ask questions of the data so — practically from the start — web servers relied on databases.
Databases were largely stateless, which is to say when you posted a query to the database even a modified query was done as a separate task. So you could ask, for example. “how many widgets did we sell last month” and get a good answer, but if you wanted a follow-up like “how many of those were blue?” your computer had to pose it as a whole new query: “how many blue widgets did we sell last month?”
You might wonder why this mattered? Who cared? Amazon.com founder Jeff Bezos cared, and his concern changed forever the world of commerce.
Amazon.com was built on the World Wide Web, which web inventor Tim Berners-Lee defined as being stateless. Why did Tim do that? Because Larry Tesler at Xerox PARC was opposed to modes. Larry’s license plate reads NO MODES, which meant as an interface guy he was opposed to having there be different modes of operation where you’d press a control key, for example, and whatever came after that was treated differently by the computer. Modes created states and states were bad so there were no states within a Xerox Alto computer. And since Tim Berners-Lee was for the most part networking together Altos at CERN to build his grandly named World Wide Web, there were no modes on the WWW, either. It was stateless.
But the stateless web created big problems for Amazon where Jeff Bezos had dreams of dis-intermediating every brick and mortar store on earth — a process that was made very difficult if you had to continually start over from the beginning. If you were an early Amazon user, for example, you may remember that when you logged-out all your session data was lost. The next time you logged-into the system (if it recognized you, which it typically didn’t) you could probably access what you had previously purchased but not what you had previously looked at.

Amazon’s obsession with the customer experience, as shown in this sketch from the company’s original business plan, was an inseparable part of its unique business model.
Bezos — a former Wall Street IT guy who was familiar with all the Business Intelligence tools of the time, wanted a system where the next time you logged-in the server would ask “are you still looking for long underwear?” It might even have sitting in your shopping cart the underwear you had considered the last time but decided not to buy. This simple expedient of keeping track of the recent past was the true beginning of Big Data.
Amazon built its e-commerce system on Oracle and spent $150 million developing the capability just described — a capability that seems like a no-brainer today but was previously impossible. Bezos and Amazon went from keeping track of what you’d bought to what you’d considered buying to what you’d looked at, to saving every keystroke and mouse click, which is what they do today, whether you are logged-in or not.
Understand we are talking about 1996 when an Internet startup cost $3-5 million venture capitalist dollars, tops, yet Amazon spent $150 million to create a Big Data buying experience where there never had been one before. How many standard deviations is that from the VC mean? Bezos, practically from the start, bet his entire company on Big Data.
It was a good bet, and that’s why Amazon.com is worth $347 billion today, with $59 billion of that belonging to Jeff Bezos.
This was the first miracle of Big Data, that Jeff Bezos was driven to create such a capability and that he and his team were able to do it on Oracle, a SQL RDBMS that had never been intended to perform such tasks.
Hi! I am a content-detection robot. This post is to help manual curators; I have NOT flagged you.
Here is similar content:
http://www.cringely.com/2016/07/05/thinking-big-data-part-one/